

引言
语义网(Semantic Web)是一种数据的网络,让数据得以共享,而不仅仅是被应用程序束缚。
但语义网也不仅仅是把数据放在互联网上,而是试图将数据联系起来,并产生数据与现实事物的联系,以方便人与机器阅读与理解这些数据。
The Semantic Web isn't just about putting data on the web. It is about making links, so that a person or machine can explore the web of data.
——Linked Data Design Issues . Tim Berners-Lee
关联数据(Linked Data)是第一种可行的语义网表达形式,它采用RDF数据模型,利用URI(统一资源标识符)命名数据实体,来发布和部署实例数据和类数据,从而可以通过HTTP协议揭示并获取这些数据,同时强调数据的相互关联、相互联系以及有益于人机理解的语境信息。
Linked data is a set of best practices for publishing and deploying instance and class data using the RDF data model, and uses uniform resource identifiers (URIs) to name the data objects. The approach exposes the data for access via the HTTP protocol, while emphasizing data interconnections, interrelationships and context useful to both humans and machine agents.
——Linked Data FAQ . M.K. Bergman
因为语义网是一项庞大的工程,并相伴着各种困难,使其成为一种长期目标与愿景,而关系数据是一类实践活动,其可行并实用,成为当前语义网实现的一种最佳可行方案。
RDF的特点
资源描述框架(Resource Description Framework),作为XML(Extensible Markup Language)的一种衍生版本,他是关联数据的基本数据模型。蒂姆·伯纳斯-李(Tim Berners-Lee)在设计它的时候面临了以下两个问题:
•怎样去设计方便易学易于传播并适合标准化的语言?
•怎样去设计离散数据的入口和出口?
为了解决这两个问题,RDF有以下一些特点:
•使用XML作为基本语言
•使用URIs作为现实事物的名字
•使用HTTP URIs使人们知道如何通过名字在网络中寻找数据(即创建离散数据入口)
•包含与其他URIs的联系,使人们可以通过其找到更多有用的东西(即创建离散数据出口)
•使用三元组(Triple)形式存储数据
实际上,一些RDF版本并非使用XML语言,这里主要指的是初始版本。
一个简单的RDF例子
复制代码 代码如下:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<rdf:Description rdf:about="http://www.w3.org/">
<dc:title>World Wide Web Consortium</dc:title>
</rdf:Description>
</rdf:RDF>
将该RDF例子通过W3C RDF验证服务,会出现以下列表:
Triples of the Data Model
| Number | Subject | Predicate | Object |
| 1 | http://www.w3.org/ | http://purl.org/dc/elements/1.1/title | "World Wide Web Consortium" |
这是啥东东?
三元组(Triple),RDF数据模型的基本表现单元。所谓三元组就是:主(Subject)-谓(Predicate)-宾(Object)。
A triple store is designed to store and retrieve identities that are constructed from triplex collections of strings (sequences of letters). These triplex collections represent a subject-predicate-object relationship that more or less corresponds to the definition put forth by the RDF standard.
——Triple Store . Jack Rusher
不同于关系数据,其数据本身没有庞大的联系(这在数据网络如此庞大的数据面前也是不可行的),而是使用类似人类陈述语句(Statement)的方式来存储数据,例如:
•Tom is a man.(Tom是个男人)
•Tom lives in a red house.(Tom住在一个红房子里)
•Tom married with Lili.(Tom和Lili结婚了)
可见三元组形式也有强大的数据存储表达潜力,人类正是这种形式的长期受益者。当然像上面这么表述对人类友好,但对机器却不怎么友好,因为这种谓语对于宾语并没有良好的限定,至少机器不这么认为。所以我们应该写成这样的模式:
•Tom(Tom) sex(性别) man(男)
•Tom(Tom) house(房子) red(红色)
•Tom(Tom) wife(妻子) Lili(Lili)
回到标题,这是什么东东?其表述了下列内容:
1.http://www.w3.org (表示该陈述是描述的主体是什么,由于HTTP URI映射现实事物,所以可以看做该是对什么现实事物的描述)
2.http://purl.org/dc/elements/1.1/title (主体的属性,一般表示宾体的类型,例如dc:title是都柏林核心中用来指明资源名称的,即客体是该资源的一个名字)
3.World Wide Web Consortium (客体)
别人是如何获得RDF的?
下图说明了这个过程:
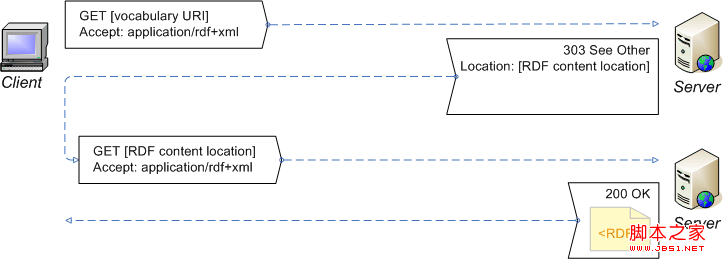
•首先先对HTTP URI进行请求。
•通常浏览器HTTP请求头是:text/html、application/xhtml+xml类型,故服务器返回一般html/xhtml文档。
•但对于语义浏览器,其HTTP请求头是:application/rdf+xml类型,故服务器进行303重定向,得到相应RDF文件。
也就是说,对于一个HTTP URI可以返回两种表达形式:文档和数据。这样就建立了两种不同的网络,一个利于人类阅读的文档网,另一种是利于机器阅读的数据网。