

一、前言
以前的系统由于表设计比较复杂(多张表,表与表直接有主从关系),这个是业务逻辑决定的。 插入效率简直实在无法忍受,必须优化。在了解了Postgre的Copy,unlogged table 特性
之后,决定一探究竟。
二、测试用例
1.数据表结构:表示一个员工工作绩效的表(work_test):共15个字段
id,no,name,sex,tel,address,provice,city,post,mobile,department,work,start_time,end_time,score
索引(b-tree的集群索引或者叫聚集索引):id,no,name,sex,tel,address,provice,city,post,mobile,department,work
2.测试环境:win7,四核,2GB内存;postgre版本9.3;Npgsql连接Postgre数据库。
三、insert/ transaction/ copy/unlogged table
1.insert 一个10W数据大概需要120s,虽然已经提升“不少”,但是还是不尽如人意。以前用SQLite时发现Transaction可以大幅提升性能,于是在Postgre中试试,发现并没有明显变
化。不知何故。
2. copy可以将文件(csv)中的数据复制进数据库中,当然数据表的结构和要数据类型要与文件一一对应。据说可以大幅提升插入性能。
复制代码 代码如下:
COPY 'work_test' from 'c:temp.csv' WITH DELIMITER AS ','
使用Copy后发现插入的性能立马提升至30s,相当于1s插入3300条记录。这中间还包含生成csv文件的时间。
3.unlogged table
unlogged table,网上的文章说可以10倍于insert。使用方法也很简单:Create unlogged table ...
但是unlogged table 在遇到Postgre服务器异常重启后会丢失全部数据,所以如果你的数据不允许丢失,请不要使用。
使用后发现,大概20s,1s插入5000条记录。
下面是三种插入方式的走势图:
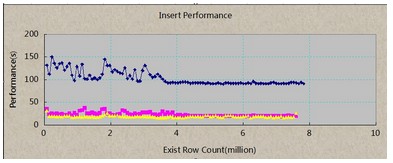
说明:x轴表示数据库中已有的记录数,单位百万,每个点是10W.Y轴表示每次插入所耗时间,单位秒。
蓝色线:insert;之所以后面比较稳定是因为电脑没有运行其他程序。所以说,电脑工作状态对Postgre效率有一定的影响。
粉红色:copy;
黄色线:copy+unlogged
虽然建了索引,并且表中的数据一直累加进来,对于后续插入数据性能并没有任何影响,这个结果就是我想看到的。
四、查询测试
按name字段搜索:
复制代码 代码如下:
select * from work_test where name='1'
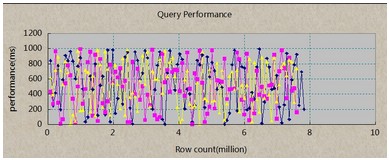
说明:x轴表示数据库中已有的记录数,单位百万,每个点是10W.Y轴表示每次查询所耗时间,单位毫秒。
蓝色线:insert;
粉红色:copy;
黄色线:copy+unlogged
由于三种插入方式结果都是一样的,所以对比并没有意义,这里主要看查询耗时。平均下来:500ms,并且随着Row count的增加,查询效率并没有降低。这主要得益于良好的索引。
另外发现:条件越多,查询效率越高,因为扫描的行数在减少,后面的图就不贴出来了。