

前段时间接到一个Web应用自动生成Word的需求,现整理了下一些关键步骤拿来分享一下。
思路:(注:这里只针对WORD2003版本,其它版本大同小异。)
因为WORD文件内部的数据及格式等是通过XML文件的形式存储的,所以WORD文件可以很方便的实现由DOC到XML格式的相互转换,而操作XML文件就方便的多了,这样就实现了与平台无关的各种操作,通过节点的查询、替换、删除、新增等生成Word文件。所以,根据模板生成WORD文件实质就是由用户数据替换XML文件中特殊标签,然后另存为一个DOC文件的过程。
下面列举涉及到的一些关键步骤(以介绍信为例)
第一步:根据需求制作WORD模板
新建一个DOC格式的WORD文件,根据需要填写好模板内容,设置好模板的格式,包括字体,样式,空行等等,需要填充的数据使用特殊标签(如:【※单位名称※】)预先占位,然后将新建的WORD文件另存为XML格式文件。这样, WORD模板就制作完成了,代码如下:
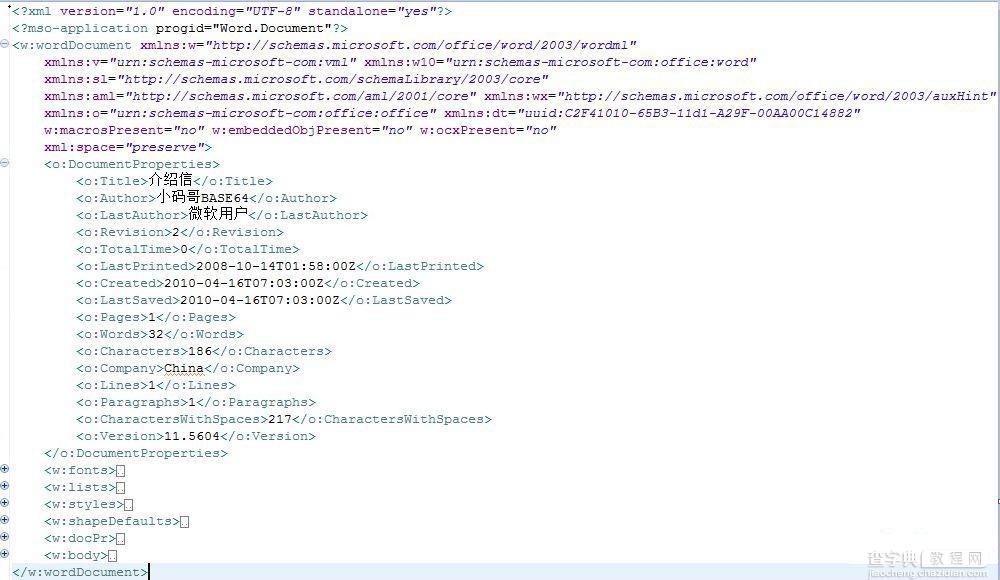 |
新增名为template-rule.xml的配置文件,每个template节点对应一个模板类型。每个template中有一个taglist节点,该节点包含的所有子节点包含了模板所有将要替换、删除节点信息,节点信息包括:节点值,节点属性英文名称,中文描述,字段类型,可否删除等信息。在设置这个配置文件时候,需要注意desc属性的值必须与模板XML中的占位符一致。比如:模板XML中设置的年份这个录入项【※年※】需与template-rule.xml中的desc="年"名称对应,代码如下:
复制代码 代码如下:
<>
<>
<templates>
<>
<template name="RECOMMEND-LETTER" desc="介绍信" templatefile="template4.xml">
<taglist remark="单值标签列表">
<tag id="1" name="ToPartment" desc="接收部门" type="S" ifemptydelete="T">#ToPartment</tag><>
<tag id="2" name="OwnerName" desc="姓名" type="S">#OwnerName</tag><>
<tag id="3" name="CountNum" desc="人数" type="S">#CountNum</tag><>
<tag id="4" name="Business" desc="内容" type="S">#Business</tag><>
<tag id="5" name="UsefulDays" desc="有效期" type="S">#UsefulDays</tag><>
<tag id="6" name="Year" desc="年" type="S">#Year</tag><>
<tag id="7" name="Month" desc="月" type="S">#Month</tag><>
<tag id="8" name="Day" desc="日" type="S">#Day</tag><>
</taglist>
</template>
</templates>
第三步:编写java代码
复制代码 代码如下:
/**
* 参数及规则
*/
public class RuleDTO {
/**
* tag名称
*/
private String parmName;
/**
* tag描述
*/
private String parmDesc;
/**
* tag序号
*/
private String parmSeq;
/**
* tag值类型
*/
private String parmType;
/**
* tag参数名称
*/
private String parmRegular;
/**
* tag值
*/
private String parmValue;
/**
* tag值为空删除该属性
*/
private String ifEmptyDelete;
}
复制代码 代码如下:
/**
* 描述: Word模板信息
*/
public class Template {
private String name;//模板名
private String desc;//模板描述
private String templateFile;//模板文件
private Vector<ruledto> rules;//模板规则
}</ruledto>
复制代码 代码如下:
public class WordBuilder {
/**
* 根据模板读取替换规则
* @param templateName 模板ID
*/
@SuppressWarnings("unchecked")
public Template loadRules(Map<string, string=""> ruleValue) {
InputStream in = null;
Template template = new Template();
// 规则配置文件路径
String ruleFile = "template-rule.xml";
// 模板规则名称
String templateRuleName = "";
try {
templateRuleName = ruleValue.get("ruleName");
// 读取模板规则文件
in = this.getClass().getClassLoader().getResourceAsStream(ruleFile);
// 解析模板规则
SAXBuilder sb = new SAXBuilder();
Document doc = sb.build(in);
Element root = doc.getRootElement(); // 得到根元素
List<element> templateList = root.getChildren();// 所有模板配置
Element element = null;
Vector<ruledto> rules = null;
for (int i = 0; i < templateList.size(); i++) {// 遍历所有模板
element = (Element) templateList.get(i);
String templateName = element.getAttributeValue("name");
if (templateRuleName.equalsIgnoreCase(templateName)) {// 查找给定的模板配置
template.setName(templateName);
template.setDesc(element.getAttributeValue("desc"));
template.setTemplateFile(element
.getAttributeValue("templateFile"));
List<element> tagList = ((Element) element.getChildren()
.get(0)).getChildren();// tag列表
Element tag = null;
RuleDTO ruleDTO = null;
rules = new Vector<ruledto>();
for (int j = 0; j < tagList.size(); j++) {
tag = (Element) tagList.get(j);
ruleDTO = new RuleDTO();
ruleDTO.setParmName(tag.getAttributeValue("name"));
ruleDTO.setParmDesc("【※"
+ tag.getAttributeValue("desc") + "※】");
ruleDTO.setParmSeq(tag.getAttributeValue("id"));
ruleDTO.setParmType(tag.getAttributeValue("type"));
if ("T".equalsIgnoreCase(tag
.getAttributeValue("ifEmptyDelete"))) {// 是否可删除标记
ruleDTO.setIfEmptyDelete("T");
} else {
ruleDTO.setIfEmptyDelete("F");
}
ruleDTO.setParmRegular(tag.getText());
// 值
// 判断参数类型
String value = (String) ((Map<string, string="">) ruleValue)
.get(ruleDTO.getParmRegular().replaceAll("#",
""));
ruleDTO.setParmValue(value);
rules.add(ruleDTO);
}
template.setRules(rules);
break;
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (JDOMException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
in.close();
} catch (Exception e) {
e.printStackTrace();
}
}
return template;
}
/**
* 查找父节点
*/
public Element findElement(Element currNode, String parentNodeId) {
// 节点标示为空
if (currNode == null || parentNodeId == null) {
return null;
}
Element pNode = null;
do {
pNode = currNode.getParent();
currNode = pNode;
} while (parentNodeId.equalsIgnoreCase(pNode.getName()));
return pNode;
}
/**
* 生成Word文件
*/
@SuppressWarnings("unchecked")
public String build(Template template) {
InputStream in = null;
OutputStream fo = null;
// 生成文件的路径
String file = "d:test" + template.getDesc() + ".doc";
try {
// 读取模板文件
in = this.getClass().getClassLoader()
.getResourceAsStream(template.getTemplateFile());
SAXBuilder sb = new SAXBuilder();
Document doc = sb.build(in);
Element root = doc.getRootElement(); // 得到根元素
Namespace ns = root.getNamespace();// NameSpace
// word 03模板存在<wx:sect>元素
List<element> sectList = root.getChild("body", ns).getChildren();
Element sectElement = (Element) sectList.get(0);
// <w:p>下的标签集合
List<element> pTagList = sectElement.getChildren("p", ns);
// <w:tbl>下的标签集合
List<element> tblTagList = sectElement.getChildren("tbl", ns);
if (pTagList != null && pTagList.size() > 0) {
changeValue4PTag(pTagList, template.getRules(), ns, null);
}
if (tblTagList != null && tblTagList.size() > 0) {
changeValue4TblTag(tblTagList, template.getRules(), ns);
}
// 写文件
XMLOutputter outp = new XMLOutputter(" ", true, "UTF-8");
fo = new FileOutputStream(file);
outp.output(doc, fo);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (JDOMException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
in.close();
fo.close();
} catch (Exception e) {
e.printStackTrace();
}
}
return file;
}
/**
* 针对<w:body><wx:sect><w:p>这种层级的WORD模板, 查找及替换<w:p>下的标签。
* @param pTagList :<w:p>集合
* @param rulesValue :RuleDTO集合
* @param ns :NameSpace对象
* @param trChildren :<w:tbl>的子节点<w:tr>集合
*/
@SuppressWarnings("unchecked")
private boolean changeValue4PTag(List<element> pTagList,
Vector<ruledto> rulesValue, Namespace ns, List<element> trChildren) {
Element p = null;
boolean delFlag = false;
for (int i = 0; i < pTagList.size(); i++) {
boolean delCurrNode = false;// 删除当前节点
boolean delCurrNode4TabWR = false;// 删除table中单行节点
p = (Element) pTagList.get(i);
List<element> pChild = p.getChildren("r", ns);
for (int j = 0; pChild != null && j < pChild.size(); j++) {
Element pChildren = (Element) pChild.get(j);
Element t = pChildren.getChild("t", ns);
if (t != null) {
String text = t.getTextTrim();
if (text.indexOf("【※") != -1) {
for (int v = 0; v < rulesValue.size(); v++) {
RuleDTO dto = (RuleDTO) rulesValue.get(v);
if (text.indexOf(dto.getParmDesc().trim()) != -1) {
// 判断属性值是否为可空删除
if ("T".equals(dto.getIfEmptyDelete())
&& StringUtils.isBlank(dto
.getParmValue())) {
// 删除该节点顶级节点
text = "";
if (trChildren != null) {// 针对<w:tbl>删除该行
Element element = ((Element) p
.getParent()).getParent();
trChildren.remove(element);
delCurrNode4TabWR = true;
} else {// 针对<w:r>删除段
// pTagList.remove(p);
pTagList.remove(pChildren);
delCurrNode = true;
}
break;
} else {
text = text.replaceAll(dto.getParmDesc()
.trim(), dto.getParmValue());
}
}
}
t.setText(text);
}
if (delCurrNode4TabWR) {// <w:tbl>TABLE下的行节点已删除
delFlag = true;
break;
} else if (delCurrNode) {// <w:p>下的节点已删除
i--;
delFlag = true;
break;
}
}
}
}
return delFlag;
}
/**
* 针对含有表格的WORD模板, 查找及替换<w:tbl>下的标签。
* @param tblTagList :<w:tbl>集合
* @param rulesValue :RuleDTO集合
* @param ns :NameSpace对象
*/
@SuppressWarnings("unchecked")
private void changeValue4TblTag(List<element> tblTagList,
Vector<ruledto> rulesValue, Namespace ns) {
Element p = null;
for (int i = 0; tblTagList != null && i < tblTagList.size(); i++) {
p = (Element) tblTagList.get(i);
List<element> trChildren = p.getChildren("tr", ns);
for (int j = 0; trChildren != null && j < trChildren.size(); j++) {// 循环<w:tr>
Element pChildren = (Element) trChildren.get(j);
List<element> tcTagList = pChildren.getChildren("tc", ns);
for (int c = 0; tcTagList != null && c < tcTagList.size(); c++) {// 循环<w:tc>取<w:p>集合
Element tcChildren = (Element) tcTagList.get(c);
List<element> pTagList = tcChildren.getChildren("p", ns);
boolean delFlag = changeValue4PTag(pTagList, rulesValue,
ns, trChildren);
if (delFlag) {// 删除行后需要改变trChildren的指针位置
j--;
}
}
}
}
}
public static void main(String[] args) throws Exception {
WordBuilder word = new WordBuilder();
Map<string, string=""> map = new HashMap<string, string="">();
//填充参数
map.put("ToPartment", "XXX公司");
map.put("OwnerName", "张三");
map.put("CountNum", "5");
map.put("Business", "例行检查");
map.put("UsefulDays", "15");
map.put("Year", "2014");
map.put("Month", "5");
map.put("Day", "13");
map.put("ruleName", "RECOMMEND-LETTER");
Template template = word.loadRules(map);
//直接打开文件
Runtime.getRuntime().exec("explorer " + word.build(template));
}
}</string,></string,></element></w:p></w:tc></element></w:tr></element></ruledto></element></w:tbl></w:tbl></w:p></w:tbl></w:r></w:tbl></element></element></ruledto></element></w:tr></w:tbl></w:p></w:p></w:p></wx:sect></w:body></element></w:tbl></element></w:p></element></wx:sect></string,></ruledto></element></ruledto></element></string,>
第四步:大功告成
几点总结及注意事项:
1. 定义的元素name必须与template_rule.xml中对应相同的name的值一致,否则需要设置转换规则。
2. 模板xml中定义的占位符【※※】中的文字必须与template_rule.xml中对应的desc相同,否则需要设置转换规则.
3. 在配置好模板XML后,需要检查标签下的子节点是否是标签(与WORD版本有关),如果没有,则必须加上该标签。
4. 如果要动态删除标签节点,则这个节点的内容需要在模板中的同一行,如果不是,则可以手动调整模板XML。
5. 如果需要实现WORD自动换行功能(关于模板中换行的方案暂没有想到更好的),则需要首先计算出对应模板该行的字数,然后采用空格填充来实现。