

书接上回,我们需要修改程序以达到连续抓取40个页面的内容。也就是说我们需要输出每篇文章的标题、链接、第一条评论、评论用户和论坛积分。
如图所示,$('.reply_author').eq(0).text().trim();得到的值即为正确的第一条评论的用户。
{<1>}

在eventproxy获取评论及用户名内容后,我们需要通过用户名跳到用户界面继续抓取该用户积分
复制代码 代码如下:
var $ = cheerio.load(topicHtml);
//此URL为下一步抓取目标URL
var userHref = 'https://cnodejs.org' + $('.reply_author').eq(0).attr('href');
userHref = url.resolve(tUrl, userHref);
var title = $('.topic_full_title').text().trim().replace(/n/g,"");;
var href = topicUrl;
var comment1 = $('.reply_content').eq(0).text().trim();
var author1 = $('.reply_author').eq(0).text().trim();
//传递参数到下一次并发抓取
ep.emit('user_html', [userHref, title, href, comment1, author1]);
在eventproxy这一次中,我们要找到score是放在哪里(class="big")。
{<2>}

找到classname就好办了,我们先试着把结果输出一下
复制代码 代码如下:
var outcome = superagent.get(userUrl)
.end(function (err, res) {
if (err) {
return console.error(err);
}
var $ = cheerio.load(res.text);
var score = $('.big').text().trim();
console.log(user[1]);
console.log(user[2]);
console.log(user[3]);
console.log(user[4]);
console.log($('.big').text().trim());
return ({
title: user[1],
href: user[2],
comment1: user[3],
author1: user[4],
score1: score
});
});
});
运行程序,这段代码得到的结果。
{<3>}

但是问题来了,我们在.end()的回调函数中能正确输出结果,但是不能正确的输出outcome。仔细一看,需要输出的outcome是一个Request对象。这是因为粗心犯的错的,.end()函数并不会传递返回值给Request对象,需要将结果返回到上一层(users)。
复制代码 代码如下:
//find userDetails
ep.after('user_html', topicUrls.length, function(users){
users = users.map(function(user){
var userUrl = user[0];
var score;
superagent.get(userUrl)
.end(function (err, res) {
if (err) {
return console.error(err);
}
//console.log(res.text);
var $ = cheerio.load(res.text);
score = $('.big').text().trim();
});
return ({
title: user[1],
href: user[2],
comment1: user[3],
author1: user[4],
score1: score
});
});
把users好好地输出发现除了score1其他是正确值。仔细调试发现,程序是先进行了console.log(),然后再进行.map()。更准确地说,在.map()函数内,.get()的回调函数并没有执行完赋值score,return 返回值就进行了。这就是回调函数的异步,而外层的同步操作是不会等待回调函数做完操作的。
{<4>}

我的做法就是eventproxy再emit一层消息,伴随着消息把需要的数据一起传递给接收消息操作.after(),只有当消息全部接收完毕,再打印出传递的参数(结果)。
复制代码 代码如下:
score = $('.big')text().trim();
//新添加
ep.emit('got_score', [user[1], user[2], user[3], user[4], score]);
.....
ep.after('got_score', 10, function(users){
console.log(users);
});
{<6>}
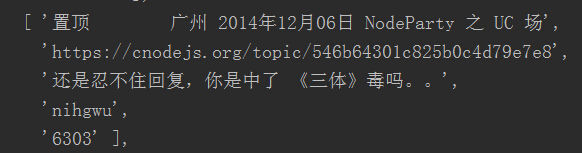
这个问题解决了,但score1的数值好像太大了点吧。再一看,原来class='big'有两个,用户的话题收藏也是属于这个class。我们得通过cheerio的.slice( start, [end] )来切取第一个元素,即将score 修改为 score = $('.big').slice(0).eq(0).text().trim();。正确结果如图。
{<7>}
