

最近,我抽空改成SyntaxHighlighter。由于coolcode插件的开头标签是
<coolcode>
或者[coolcode]这样的,而SyntaxHighlighter是
[code lang="php"]
这样的(或者其他)。遂只能想办法把老的格式转化成新的格式。当然,肯定用到正则表达式了。
原来的代码高亮开头标识为
<coolcode lang="php" download="123.php" linenum="on"><coolcode lang="php" linenum="off"><coolcode lang="php">
这种类型的,
而SyntaxHighlighter的标识为
[code lang="php"]
那根据要求写的正则表达式为
<coolcode lang="[a-z]+".*?>
解释一下
复制代码 代码如下:
[a-z]+ 匹配 php,javascript,cpp,sql,css 等,后面的.*?中的 .表示任何除了换行之外的字符,而*表示0次或者无数次,*+这些表述次数的符号后面接的?标识非贪婪模式
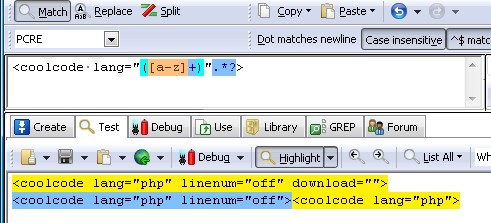
看图,这个正则可以实现上述要求了。
但是,问题还没解决,我们还有一种情况没考虑,那就是
<coolcode
后面不一定接的就是lang="php"这样的属性啊,有可能是download,也有可能是linenum="on/off"啊,所以,我们的正则还需要改。
CFC4N把正则改为
<coolcode.*?lang="[a-z]+".*?>
截图如下
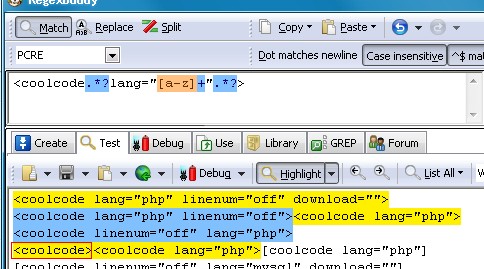
细心的朋友可能看出来图中匹配的红色框内多出了
<coolcode
,意思也就是说,前面的
<coolcode>
需要排除掉。如何排除呢?聪明的你肯定立刻想到.这个万能字符替换成非<>两个符号的规则,好,CFC4N立刻修改一下。
修改之后的正则为
<coolcode.*?lang="[a-z]+".*?>
果然,匹配正常了。结果见截图。
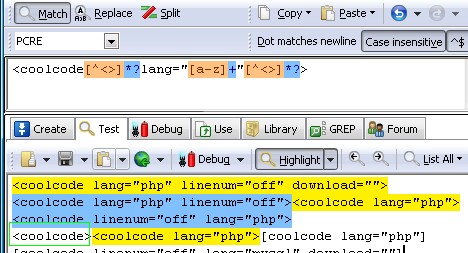
到这里,问题似乎解决了,可是,当初糊涂的我,把coolcode的两种开头标识都用了,那就是
<coolcode
和[coolcode,那么,看官您认为这个正则该如何改写呢?
没错,无非就是开头,结尾的标识考虑两种情况<和[,那么正则就好改了。(别忘了排除规则里的符号哦)
[<[]coolcode[^<>[]]*?lang="[a-z]+"[^<>[]]*?[>]]
嗯,好,我们来看下效果:
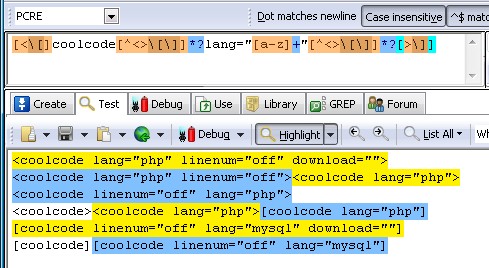
很好很完美。
下面,就可以去执行了。
可是,我遇到一个很意外的事情。居然发现老的代码里包含这样的格式
[coolcode linenum="off" lang="cpp"]<coolcode download="" lang="cpp" linenum="off">
呃,问题在这里了,只是多了个转义字符罢了,那么,改起来,也简单。也就是允许出现0次或者一次,而标识0次或者1次的符号为?,那么我们直接在后面加个?,也就是改成这样?就可以了吗?
显然,不是。在正则表达式里,也表示转义,那么,匹配的话,也得转义一下,则应该为? 这样才对。
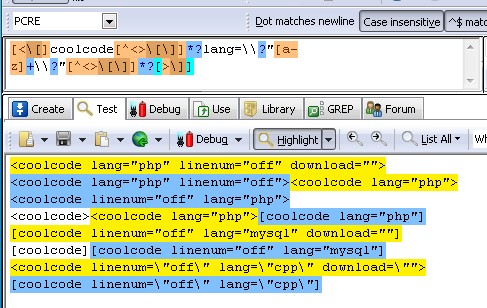
修改后正则为
[<[]coolcode[^<>[]]*?lang=?"[a-z]+?"[^<>[]]*?[>]]
匹配结果见下图:
现在,大功告成了。我们可以进行转换了。关于转换,我们可以用两种方法。
•Mysql的REPLACE函数,单个的去替换
<coolcode lang="php/cpp/javascript/sql/css等" download="name" linenum="on/off">
为对应的
[code lang="php/cpp/javascript/sql/css等"]
,这样操作,省的去写程序,取出,替换,再写入了,缺点是量大,手工也挺累,体力活。mysql仅仅支持正则查询,不支持正则查询的替换,我们也可以构造联合嵌套的SQL来替换正则匹配的字符串,但是无法取出php/cpp/javascrip这样的语言标记,替换为新的语言标记。也就是说,mysql不支持正则表达式的反向引用。
•PHP读数据库,替换,再写入。PHP的preg_replace函数支持反向引用(preg_replace不支持自定义组名的反向引用),我们只好写个查询语句,查询包含coolcode标识的文章,然后再替换,当然,直接查询包含coolcode的文章可能太多,我们也可以写个MYSQL支持的POSIX正则引擎的表达式,来匹配使用coolcode标签的文章,再来替换,写入。以减少文章的操作量。当然正则表达式也会浪费很大的资源。
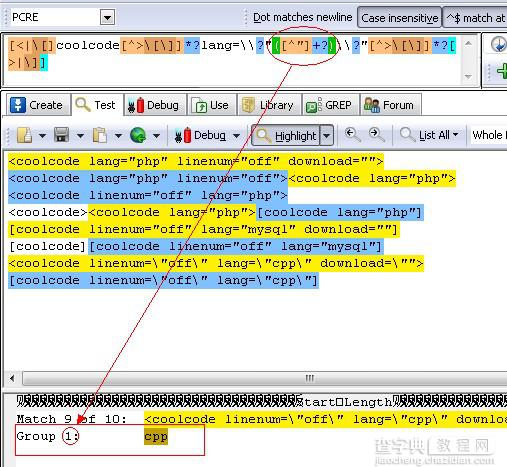
当然,在PHP代码的preg_replace函数使用上面的正则,进行反向引用时,需要对正则稍作修改。给lang=""中间的一个组名。正则修改为
[<[]coolcode[^<>[]]*?lang=?"([a-z]+?)"[^<>[]]*?[>]]
PHP的替换代码为
$contents = preg_replace('/[<|[]coolcode[^>[]]*?lang=?"([^"]+?)?"[^>[]]*?[>|]]/i','[code lang="1"',$contents);
其中正则的i修饰符标识不区分大小写。
还有,别忘记了coolcode的结束标识和[/coolcode]要替换成[/code]。
mysql里执行两句sql即可
复制代码 代码如下:
UPDATE wp_posts SET post_content = REPLACE(post_content,'</coolcode>','[/code]'); //注意后面多了个反斜杠,记得去掉
UPDATE wp_posts SET post_content = REPLACE(post_content,'[/coolcode]','[/code]'); //注意后面多了个反斜杠,记得去掉
总结:
本文牵扯的正则表达式并无高级用法,都是平常很简单的用法。关于PCRE引擎正则表达式的递归(迭代),组命名,反向引用,零宽断言等,CFC4N会在以后的时间里,找合适的例子写出来。当然,这些高级用法,CFC4N在帮朋友写的正则表达式里已经用到了,大家可以看看,欢迎批评和指点。
PS:如果需要coolcode转SyntaxHighlighter的完整PHP程序,留言即可,我抽空写出来。