

前言
本节我们讲讲一些简单查询语句示例以及需要注意的地方,简短的内容,深入的理解。
EOMONTH
在SQL Server 2012的教程示例中,对于Sales.Orders表的查询,需要返回每月最后一天的订单。我们普遍的查询如下
USE TSQL2012 GO SELECT orderid, orderdate, custid, empid FROM Sales.Orders WHERE orderdate = DATEADD(MONTH, DATEDIFF(MONTH, '19991231', orderdate), '19991231')
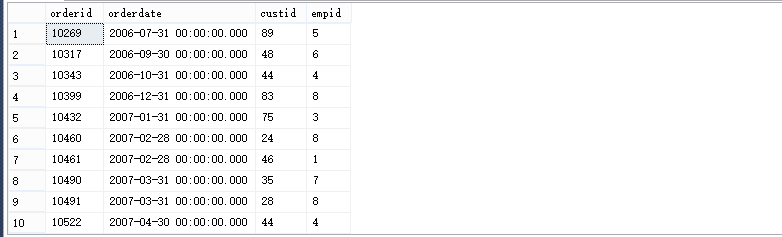
但是在SQL Server 2012出现了新的函数直接返回每个月最后一天的订单,通过EOMONTH函数即可,将
WHERE orderdate = DATEADD(MONTH, DATEDIFF(MONTH, '19991231', orderdate), '19991231')
替换为
SELECT orderid, orderdate, custid, empid FROM Sales.Orders WHERE orderdate = EOMONTH(orderdate)
如上简单而粗暴。
HAVING AND WHERE
我们利用Sales.OrderDetails表来查询总价(qty*unitprice)大于10000的订单,且按照总价排序。
USE TSQL2012 GO SELECT orderid,SUM(unitprice *qty) AS TotalValue FROM Sales.OrderDetails GROUP BY orderid HAVING SUM(unitprice *qty) > 10000 ORDER BY TotalValue DESC

通过此例我们来说说WHERE和HAVING的区别,下面的示例是等同的
SELECT orderid FROM Sales.OrderDetails WHERE orderid >10357 GROUP BY orderid SELECT orderid FROM Sales.OrderDetails GROUP BY orderid HAVING orderid >10357
但是利用聚合函数时能等同吗?
SELECT orderid FROM Sales.OrderDetails WHERE COUNT(qty * unitprice) >10000 GROUP BY orderid SELECT orderid FROM Sales.OrderDetails GROUP BY orderid HAVING COUNT(qty * unitprice) >10000

二者的区别我们总结一下:
(1)WHERE能够用在UPDATE、DELETE、SELECT语句中,而HAVING只能用在SELECT语句中。
(2)WHERE过滤行在GROUP BY之前,而HAVING过滤行在GROUP BY之后。
(3)WHERE不能用在聚合函数中,除非该聚合函数位于HAVING子句或选择列表所包含的子查询中。
说了这么多,关于WHERE和HAVING的区别,其实WHERE的应用场景更多,我们归根结底一句话来概括的HAVING的用法即可。
HAVING仅仅在SELECT语句中对组(GROUP BY)或者聚合函数(AGGREGATE)进行过滤
INSERT TOP分析
当将查询出的数据插入到表中,我们其实有两种解决方案。
方案一
NSERT INTO TABLE … SELECT TOP (N) Cols… FROM Table
方案二
INSERT TOP(N) INTO TABLE … SELECT Cols… FROM Table
方案一是需要查询几条就插入几条,方案二则是查询所有我们需要插入几条数据,接下来我们来看看二者不同以及二者性能问题,创建查询表并插入数据。
CREATE TABLE TestValue(ID INT) INSERT INTO TestValue (ID) SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5
需要插入的两个表
USE TSQL2012 GO CREATE TABLE InsertTestValue (ID INT) CREATE TABLE InsertTestValue1 (ID INT)
方案一的插入
INSERT INTO InsertTestValue (ID) SELECT TOP (2) ID FROM TestValue ORDER BY ID DESC GO
方案二的插入
INSERT TOP (2) INTO InsertTestValue1 (ID) SELECT ID FROM TestValue ORDER BY ID DESC GO
接下来查询方案一和方案二的数据
SELECT * FROM InsertTestValue GO SELECT * FROM InsertTestValue1 GO

我们对方案一和方案二插入数据之前我们对查询的数据是进行了降序,此时我们能够很明显的看到方案一中的查询数据确确实实是降序,而方案二则忽略了降序,这是个很有意思的地方,至此我们看到了二者的不同。
二者性能比较
在插入数据时我们对其进行开销分析如下:
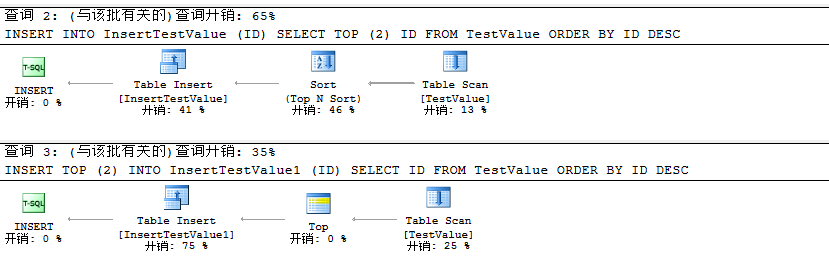
到这里我们能够知道利用INSET TOP (N)比INSERT … SELECT TOP (N)性能更好,同时SELECT TOP(N)会对查询出的数据排序进行忽略。至此我们可以得出如下结论
结论:INSERT TOP (N)比INSERT … SELECT TOP (N)插入数据性能更好。
COUNT(DISTINCT) AND COUNT(ALL)
关于DISTINCT就不用多讲,此关键字过滤重复针对的是所有列数据一致才过滤而不是针对于单列数据一致才过滤,我们看看COUNT(DISTINCT)和COUNT(ALL)查询出的数据是一致还是不一致呢?我们首先创建测试表
CREATE TABLE TestData ( Id INT NOT NULL IDENTITY PRIMARY KEY, NAME VARCHAR(max) NULL );
插入如下测试数据

接下来我们进行如下查询
USE TSQL2012 GO SELECT COUNT(NAME) AS COUNT_NAME FROM dbo.TestData SELECT COUNT(ALL NAME) AS COUNT_ALLNAME FROM dbo.TestData SELECT COUNT(DISTINCT NAME) AS COUNT_DISTINCTNAME FROM dbo.TestData

此时我们能够很清楚的看到COUNT(colName)和COUNT(ALL colName)的结果是一样的,其实COUNT(ALL colName)是默认的选项且包括所有非空值,换句话说ALL根本不需要我们去指定。
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流,同时也希望多多支持查字典教程网!