

前言
上一节我们讲解了数据类型以及字符串中几个需要注意的地方,这节我们继续讲讲字符串行数同时也讲其他内容和穿插的内容,简短的内容,深入的讲解。(可参看文章《详解SQL Server中的数据类型》)
分页方式
在SQL 2005或者SQL 2008中我们是利用ROW_NUMBER开窗函数来进行分页的,关于开窗函数,我们在SQL进阶中会详细讲讲。如下:
USE TSQL2012 GO DECLARE @StartRow INT DECLARE @EndRow INT SET @StartRow = 31 SET @EndRow = 40 SELECT [address], [city], [region] FROM ( SELECT [SC].[address], [SC].[city], [SC].[region], ROW_NUMBER() OVER( ORDER BY [SC].[address], [SC].[city],[SC].[custid]) AS RowNumber FROM Sales.Customers SC) SaleCustomer WHERE RowNumber > @StartRow AND RowNumber < @EndRow ORDER BY [address], [city], [region];
上面代码想必就不需要我解释了,同时利用视图也可以进行分页
WITH SaleCustomer AS ( SELECT [SC].[address], [SC].[city], [SC].[region], ROW_NUMBER() OVER( ORDER BY [SC].[address], [SC].[city],[SC].[custid]) AS RowNumber FROM Sales.Customers SC) SELECT [address], [city], [region] FROM SaleCustomer WHERE RowNumber > @StartRow AND RowNumber < @EndRow ORDER BY [address], [city], [region] GO
下面我们来看看这二者利用SQL查询语句和视图有没有性能上的差异呢?来,检验就是。

从这里我们可以看出,二者在性能开销上并没有什么不同,大部分情况下应该是一样的。但是在SQL 2011之后版本则出现新的语法来实现分页,估计我们依然还是利用的ROW_NUMBER,可能是为了能够兼容SQL版本到2005,利用OFFSET-FETCH来进行筛选过滤,它是基于SQL 2011之后才有。上述我们是取从31到40之间的数据,如果用OFFSET-FETCH实现,我们看这个函数字面意思就能知道跳过多少数据然后抓取多少数据,所以我们需要跳过前面30条数据,需要取接下来10条数据。
USE TSQL2012 GO DECLARE @PageSize INT = 10, @PageIndex INT = 3 SELECT * FROM Sales.Customers ORDER BY custid OFFSET @PageIndex * @PageSize ROWS FETCH NEXT 10 ROWS ONLY GO
如果对SQL版本要求不低的话,利用OFFSET-FETCH来实现简直爽爆了。
COALESCE compare to ISNULL
上一节我们讲了讲一些字符串函数,其中漏掉了一个字符串函数即COALESCE,这个函数在SQL 2008+上才有,其中还有其他几个类似对字符串函数的处理,我们一起来看下。msdn对其定义为:按顺序计算变量并返回最初不等于 NULL 的第一个表达式的当前值。返回数据类型优先级最高的 expression 的数据类型。 如果所有表达式都不可为 Null,则结果的类型也不可为 Null。如果所有参数均为 NULL,则 COALESCE 返回 NULL。至少应有一个 Null值为NULL 类型。说白了就是对NULL的处理。我们简单来看下一个例子。
USE TSQL2012 GO SELECT custid, country, region, city, country + COALESCE(N''+ region, N'') + N',' + city AS location FROM Sales.Customers

上述我们可以看到,我们通过COALESCE函数来对NULL用空字符串来代替进行处理。SQL 2012也引入了CONCAT函数来接收一个要连接的输入列表并自动以空字符串替换NULL,上述同样可以用CONCAT函数来代替。
USE TSQL2012 GO SELECT custid, country, region, city, country + CONCAT(country,N''+ region, N',' + city) AS location FROM Sales.Customers
同时我们看到下图知道,CONCAT函数参数至少要有两个:

msdn对CONCAT函数解释为:CONCAT 采用可变数量的字符串参数,并将它们串联成单个字符串。 它需要至少两个输入值;否则将引发错误。 所有参数都隐式转换为字符串类型,然后串联在一起。 Null 值被隐式转换为空字符串。 如果所有参数都为 Null,则返回 varchar(1) 类型的空字符串。 隐式转换为字符串的过程遵循现有的数据类型转换规则。
我们继续回到COALESCE函数,主要看看它与ISNULL函数的区别。
COALESCE与ISNULL函数探讨
可能有些人认为ISNULL比COALESCE函数更快,或者有人认为ISNULL和COALESCE函数是等同,更有人认为应该倾向于使用COALESCE函数,因为它是 ANSI SQL标准函数。认为归认为,那么两者到底有何不同呢,我们一起来看下。
(1)COALESCE和ISNULL处理数据类型优先不同
COALESCE函数决定类型输出基于数据类型优先【data type precedence】,所以如下在处理INT时,DATETIME优先级高于INT。
DECLARE @int INT, @datetime DATETIME; SELECT COALESCE(@datetime, 0); SELECT COALESCE(@int, CURRENT_TIMESTAMP);

而对于ISNULL函数,数据类型不受数据类型优先影响,而是通过函数参数列表第一项影响,ISNULL在于交换而COALESCE在于所有参数查询的合并。
DECLARE @int INT, @datetime DATETIME; SELECT ISNULL(@datetime, 0);

我们看看进行如下操作会如何
DECLARE @int INT, @datetime DATETIME; SELECT ISNULL(@int, CURRENT_TIMESTAMP);
此时会出现无法将DATETIME转换为INT

此时我们需要显式进行如下转换才行
DECLARE @int INT, @datetime DATETIME; SELECT ISNULL(@int, CONVERT(INT,CURRENT_TIMESTAMP)); SELECT ISNULL(@int, CAST(CURRENT_TIMESTAMP AS INT));
(2)ISNULL会造成数据丢失
我们再来看二者的对比的例子
DECLARE @c5 VARCHAR(5); SELECT 'COALESCE', COALESCE(@c5, 'Jeffcky Wang') UNION ALL SELECT 'ISNULL', ISNULL(@c5, 'Jeffcky Wang');

上述我们定义字符串变量长度为5,而利用ISNULL字符串却被截取了,在这里我们可以认为ISNULL会导致数据的丢失而非出错。为什么会出现这样的结果呢?上述我们已经讲过ISNULL受第一个参数影响,其长度定义为5,所以只能为5,这是会进行截取,而COALESCE函数着眼于检测所有元素,此时为12所以会完全进行返回。我们通过运行如下就可以看出。
DECLARE @c5 VARCHAR(5); SELECT c = COALESCE(@c5, 'Jeffcky Wang'), i = ISNULL(@c5, 'Jeffcky Wang') INTO dbo.TestISNULL_COALESCE SELECT name, t = TYPE_NAME(system_type_id), max_length, is_nullable FROM sys.columns WHERE [object_id] = OBJECT_ID('dbo.TestISNULL_COALESCE');

我们看到上述COALESCE合并的结果是可空的而ISNULL不是,有一点点不同。
(3)COALESCE对列计算时需要持久化
接下来我们看看二者最大的不同,我们通过计算列并且在其上面创建主键或者非空约束,看看ISNULL和COALESCE的区别
CREATE TABLE dbo.CreateISNULL ( a INT, b AS ISNULL(a, 15) PRIMARY KEY );

我们再来看看COALESCE函数来计算列
CREATE TABLE dbo.CreateCOALESCE ( a INT, b AS COALESCE(a, 15) PRIMARY KEY );

很明显我们需要对列进行持久化,通过添加PERSISTED关键字,如下即可。
CREATE TABLE dbo.CreateCOALESCE ( a INT, b AS COALESCE(a, 15) PERSISTED PRIMARY KEY );
我们再来看看一个二者的不同
DECLARE @c CHAR(10); SELECT 'x' + COALESCE(@c, '') + 'y'; SELECT 'x' + ISNULL(@c, '') + 'y';

我们到这里其实我们可以稍微概括下二者的区别:ISNULL着重于替换,而COALESCE着重于合并。COALESCE显示忽略了NULL并用空字符串填充并压缩,而ISNULL对NULL会用空字符串填充但不会压缩。
(4)COALESCE函数支持超过两个参数
对于多个参数输入,ISNULL函数需要嵌套调用,而COALESCE能够处理任何数量,至于上限不知,所以对于多个参数使用COALESCE更加,如下使用多个参数输入。
SELECT COALESCE(a, b, c, d, e, f, g) FROM dbo.table;
而对于ISNULL,我们需要这样做
SELECT ISNULL(a, ISNULL(b, ISNULL(c, ISNULL(d, ISNULL(e, ISNULL(f, g)))))) FROM dbo.table;
二者最终执行时和利用CASE一样
CASE WHEN [tempdb].[dbo].[table].[a] IS NOT NULL THEN [tempdb].[dbo].[table].[a] ELSE CASE WHEN [tempdb].[dbo].[table].[b] IS NOT NULL THEN [tempdb].[dbo].[table].[b] ELSE CASE WHEN [tempdb].[dbo].[table].[c] IS NOT NULL THEN [tempdb].[dbo].[table].[c] ELSE CASE WHEN [tempdb].[dbo].[table].[d] IS NOT NULL THEN [tempdb].[dbo].[table].[d] ELSE CASE WHEN [tempdb].[dbo].[table].[e] IS NOT NULL THEN [tempdb].[dbo].[table].[e] ELSE CASE WHEN [tempdb].[dbo].[table].[f] IS NOT NULL THEN [tempdb].[dbo].[table].[f] ELSE [tempdb].[dbo].[table].[g] END END END END END END
(5)COALESCE和ISNULL二者性能比较
我们来运行如下查询
DBCC DROPCLEANBUFFERS; DECLARE @a VARCHAR(5), -- = 'str_a', -- this line changed per test @b VARCHAR(5), -- = 'str_b', -- this line changed per test @v VARCHAR(5), @x INT = 0, @time DATETIME2(7) = SYSDATETIME(); WHILE @x <= 500000 BEGIN SET @v = COALESCE(@a, @b); --COALESCE SET @x += 1; END SELECT DATEDIFF(MILLISECOND, @time, SYSDATETIME()); GO DBCC DROPCLEANBUFFERS; DECLARE @a VARCHAR(5), -- = 'str_a', -- this line changed per test @b VARCHAR(5), -- = 'str_b', -- this line changed per test @v VARCHAR(5), @x INT = 0, @time DATETIME2(7) = SYSDATETIME(); WHILE @x <= 500000 BEGIN SET @v = ISNULL(@a, @b); --ISNULL SET @x += 1; END SELECT DATEDIFF(MILLISECOND, @time, SYSDATETIME());
我们有查询四个场景:(1)两个参数都为NULL(2)第一个参数为NULL(3)第二个参数为NULL(4)两个参数都为NULL。每个场景测试十次,最终得出如下结果

从上看出二者性能并未有什么太大差异,我们不需要太担心了吧,当然上述场景并未完全覆盖,至少还是能说明一部分。上述我们得到的结果查看的执行时间,现在我们再来看看二者查询执行计划。
SELECT COALESCE((SELECT MAX(index_id) FROM sys.indexes WHERE [object_id] = t.[object_id]), 0) FROM sys.tables AS t; SELECT ISNULL((SELECT MAX(index_id) FROM sys.indexes WHERE [object_id] = t.[object_id]), 0) FROM sys.tables AS t;
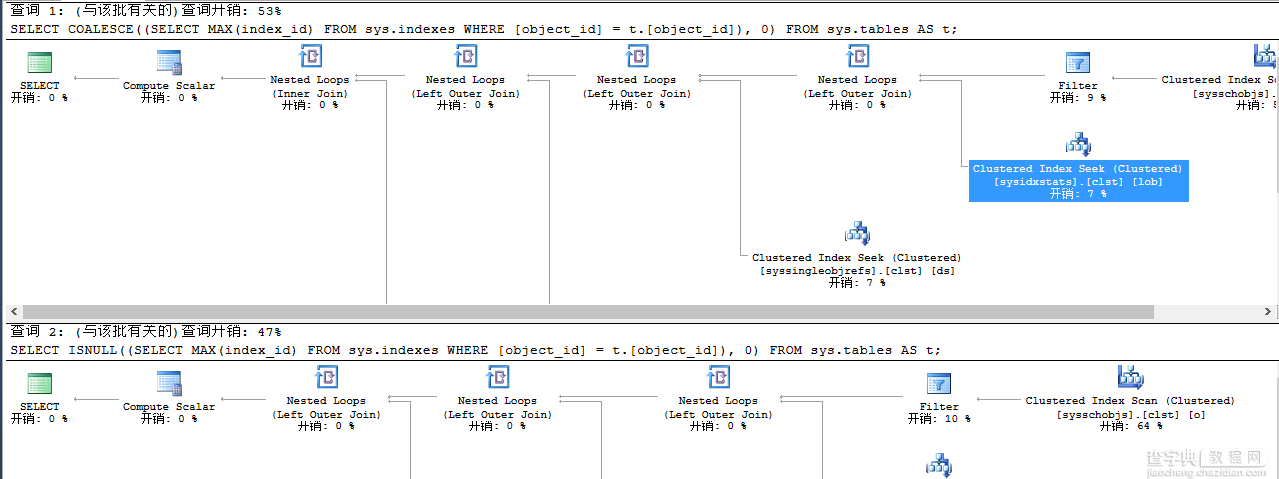
上述可能不太准确,还和硬件配置有关,也有可能COALESCE的性能差与ISNULL。二者性能应该是没什么很大差异。
(6)ISNULL和自然语言描述不一致
为何是和自然语言描述不一致呢?也就是说我们当判断某个值为NULL会做什么,不为NULL再做什么,这时用查询语言SQL描述如下:
IF ISNULL(something) -- do something
我们用自然语言角度来看,翻译为如果something为NULL我们做什么,这个时候是不一致的。因为在SQL Server中没有布尔值类型,上述我们只能进行如下转换
IF something IS NULL -- do something -- or IF ISNULL(something, NULL) IS NULL -- do something -- or IF ISNULL(something, '') = '' -- do something
(7)利用GUID看看奇葩的ISNULL
在本节介绍之前我们再来看看一个例子,从而颠覆你的想法,让你发狂。
SELECT ISNULL(NEWID(), 'JeffckyWang') AS Col1

这样看是没问题,我们将其插入到表中,再看对其列的描述
SELECT ISNULL(NEWID(), 'JeffckyWang') AS Col1 INTO dbo.IsNullExample2; EXEC sp_help 'dbo.IsNullExample2';
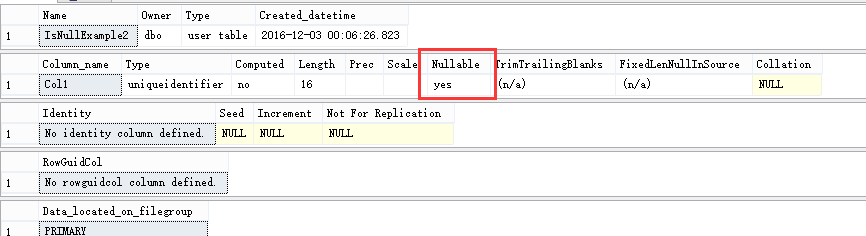
表中数据确实存在,但是对列的描述是可空的。
总结
上述重点讲述了COALESCE和ISNULL函数区别之处,通过本节的讲述二者的场景和区别,我们是不是应该有了一点想法,到底是该用COALESCE还是ISNULL呢?大部分情况下还是利用COALESCE为好,一是此函数是作为SQL标准函数,第二个相对于ISNULL它可以支持更多参数,而ISNULL则需要嵌套,而对于ISNULL难道就没有应用场景了吗,当然有在查询数据时判断数据是否为NULL,这种情况下利用ISNULL,例如,如下
SELECT ISNULL(argument, '') INTO dbo.IsNullExample;
本文关于ISNULL和COALESCE的比较参考文章:Deciding between COALESCE and ISNULL in SQL Server。本节我们到此结束,简短的内容,深入的理解,我们下节再会,good night!
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流,同时也希望多多支持查字典教程网!