

简介
这是一篇有关如何将大量的数据放入有限的内存中的简略教程。
与客户工作时,有时会发现他们的数据库实际上只是一个csv或Excel文件仓库,你只能将就着用,经常需要在不更新他们的数据仓库的情况下完成工作。大部分情况下,如果将这些文件存储在一个简单的数据库框架中或许更好,但时间可能不允许。这种方法对时间、机器硬件和所处环境都有要求。
下面介绍一个很好的例子:假设有一堆表格(没有使用Neo4j、MongoDB或其他类型的数据库,仅仅使用csvs、tsvs等格式存储的表格),如果将所有表格组合在一起,得到的数据帧太大,无法放入内存。所以第一个想法是:将其拆分成不同的部分,逐个存储。这个方案看起来不错,但处理起来很慢。除非我们使用多核处理器。
目标
这里的目标是从所有职位中(大约1万个),找出相关的的职位。将这些职位与政府给的职位代码组合起来。接着将组合的结果与对应的州(行政单位)信息组合起来。然后用通过word2vec生成的属性信息在我们的客户的管道中增强已有的属性。
这个任务要求在短时间内完成,谁也不愿意等待。想象一下,这就像在不使用标准的关系型数据库的情况下进行多个表的连接。
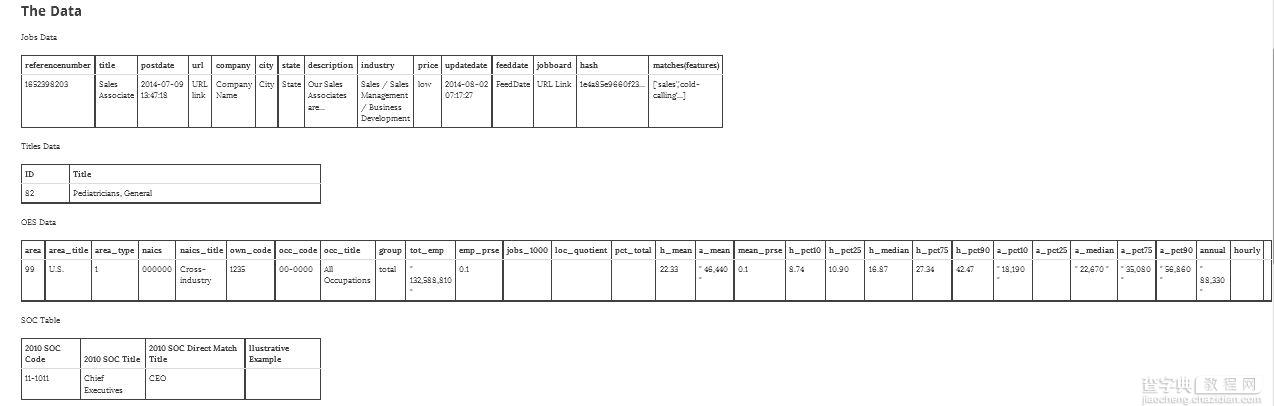
数据
示例脚本
下面的是一个示例脚本,展示了如何使用multiprocessing来在有限的内存空间中加速操作过程。脚本的第一部分是和特定任务相关的,可以自由跳过。请着重关注第二部分,这里侧重的是multiprocessing引擎。
#import the necessary packages import pandas as pd import us import numpy as np from multiprocessing import Pool,cpu_count,Queue,Manager # the data in one particular column was number in the form that horrible excel version # of a number where '12000' is '12,000' with that beautiful useless comma in there. # did I mention I excel bothers me? # instead of converting the number right away, we only convert them when we need to def median_maker(column): return np.median([int(x.replace(',','')) for x in column]) # dictionary_of_dataframes contains a dataframe with information for each title; e.g title is 'Data Scientist' # related_title_score_df is the dataframe of information for the title; columns = ['title','score'] ### where title is a similar_title and score is how closely the two are related, e.g. 'Data Analyst', 0.871 # code_title_df contains columns ['code','title'] # oes_data_df is a HUGE dataframe with all of the Bureau of Labor Statistics(BLS) data for a given time period (YAY FREE DATA, BOO BAD CENSUS DATA!) def job_title_location_matcher(title,location): try: related_title_score_df = dictionary_of_dataframes[title] # we limit dataframe1 to only those related_titles that are above # a previously established threshold related_title_score_df = related_title_score_df[title_score_df['score']>80] #we merge the related titles with another table and its codes codes_relTitles_scores = pd.merge(code_title_df,related_title_score_df) codes_relTitles_scores = codes_relTitles_scores.drop_duplicates() # merge the two dataframes by the codes merged_df = pd.merge(codes_relTitles_scores, oes_data_df) #limit the BLS data to the state we want all_merged = merged_df[merged_df['area_title']==str(us.states.lookup(location).name)] #calculate some summary statistics for the time we want group_med_emp,group_mean,group_pct10,group_pct25,group_median,group_pct75,group_pct90 = all_merged[['tot_emp','a_mean','a_pct10','a_pct25','a_median','a_pct75','a_pct90']].apply(median_maker) row = [title,location,group_med_emp,group_mean,group_pct10,group_pct25, group_median, group_pct75, group_pct90] #convert it all to strings so we can combine them all when writing to file row_string = [str(x) for x in row] return row_string except: # if it doesnt work for a particular title/state just throw it out, there are enough to make this insignificant 'do nothing'
这里发生了神奇的事情:
#runs the function and puts the answers in the queue def worker(row, q): ans = job_title_location_matcher(row[0],row[1]) q.put(ans) # this writes to the file while there are still things that could be in the queue # this allows for multiple processes to write to the same file without blocking eachother def listener(q): f = open(filename,'wb') while 1: m = q.get() if m =='kill': break f.write(','.join(m) + 'n') f.flush() f.close() def main(): #load all your data, then throw out all unnecessary tables/columns filename = 'skill_TEST_POOL.txt' #sets up the necessary multiprocessing tasks manager = Manager() q = manager.Queue() pool = Pool(cpu_count() + 2) watcher = pool.map_async(listener,(q,)) jobs = [] #titles_states is a dataframe of millions of job titles and states they were found in for i in titles_states.iloc: job = pool.map_async(worker, (i, q)) jobs.append(job) for job in jobs: job.get() q.put('kill') pool.close() pool.join() if __name__ == "__main__": main()
由于每个数据帧的大小都不同(总共约有100Gb),所以将所有数据都放入内存是不可能的。通过将最终的数据帧逐行写入内存,但从来不在内存中存储完整的数据帧。我们可以完成所有的计算和组合任务。这里的“标准方法”是,我们可以仅仅在“job_title_location_matcher”的末尾编写一个“write_line”方法,但这样每次只会处理一个实例。根据我们需要处理的职位/州的数量,这大概需要2天的时间。而通过multiprocessing,只需2个小时。
虽然读者可能接触不到本教程处理的任务环境,但通过multiprocessing,可以突破许多计算机硬件的限制。本例的工作环境是c3.8xl ubuntu ec2,硬件为32核60Gb内存(虽然这个内存很大,但还是无法一次性放入所有数据)。这里的关键之处是我们在60Gb的内存的机器上有效的处理了约100Gb的数据,同时速度提升了约25倍。通过multiprocessing在多核机器上自动处理大规模的进程,可以有效提高机器的利用率。也许有些读者已经知道了这个方法,但对于其他人,可以通过multiprocessing能带来非常大的收益。顺便说一句,这部分是skill assets in the job-market这篇博文的延续。