

有时候我们需要把一些经典的东西收藏起来,时时回味,而Coursera上的一些课程无疑就是经典之作。Coursera中的大部分完结课程都提供了完整的配套教学资源,包括ppt,视频以及字幕等,离线下来后会非常便于学习。很明显,我们不会去一个文件一个文件的下载,只有傻子才那么干,程序员都是聪明人!
那我们聪明人准备怎么办呢?当然是写一个脚本来批量下载了。首先我们需要分析一下手工下载的流程:登录自己的Coursera账户(有的课程需要我们登录并选课后才能看到相应的资源),在课程资源页面里,找到相应的文件链接,然后用喜欢的工具下载。
很简单是吧?我们可以用程序来模仿以上的步骤,这样就可以解放双手了。整个程序分为三个部分就可以了:
登录Coursera;在课程资源页面里面找到资源链接;根据资源链接选择合适的工具下载资源。
下面就来具体的实现以下吧!
登录
刚开始时自己并没有添加登录模块,以为访客就可以下载相应的课程资源,后来在测试comnetworks-002这门课程时发现访客访问资源页面时会自动跳转到登录界面,下图是chrome在隐身模式访问该课程资源页面时的情况。
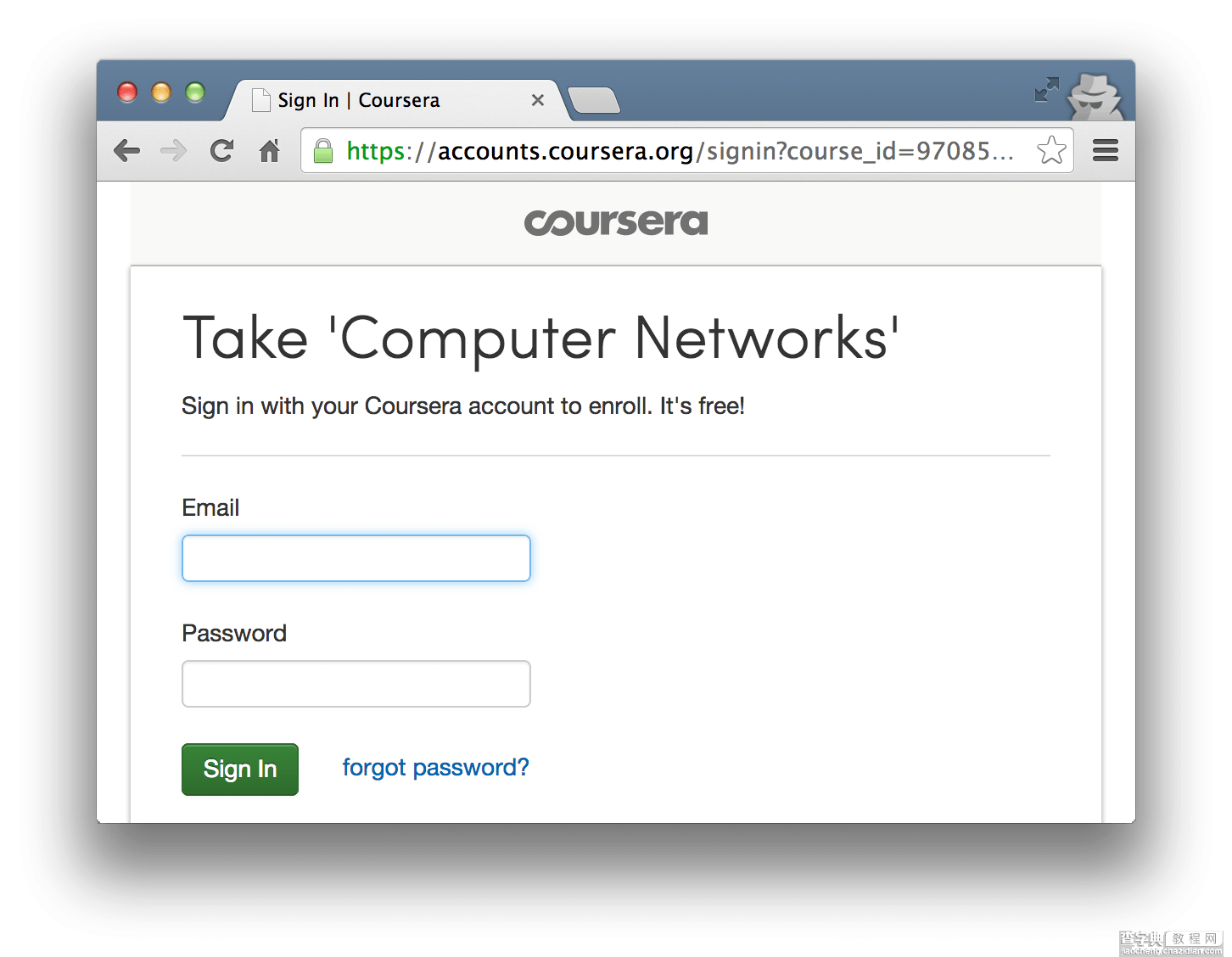
要想模拟登录,我们先找到登录的页面,然后利用google的Developer Tools分析账号密码是如何上传到服务器的。
我们在登录页面的表单中填入账号密码,然后点击登录。与此同时,我们需要双眼紧盯Developer Tools——Network,找到提交账号信息的url。一般情况下,如果要向服务器提交信息,一般都用post方法,这里我们只需要先找到Method为post的url。悲剧的是,每次登录账号时,Network里面都找不到提交账户信息的地址。猜测登录成功后,直接跳转到登录成功后的页面,想要找的内容一闪而过了。
于是就随便输入了一组账号密码,故意登录失败,果真找到了post的页面地址,如下图:
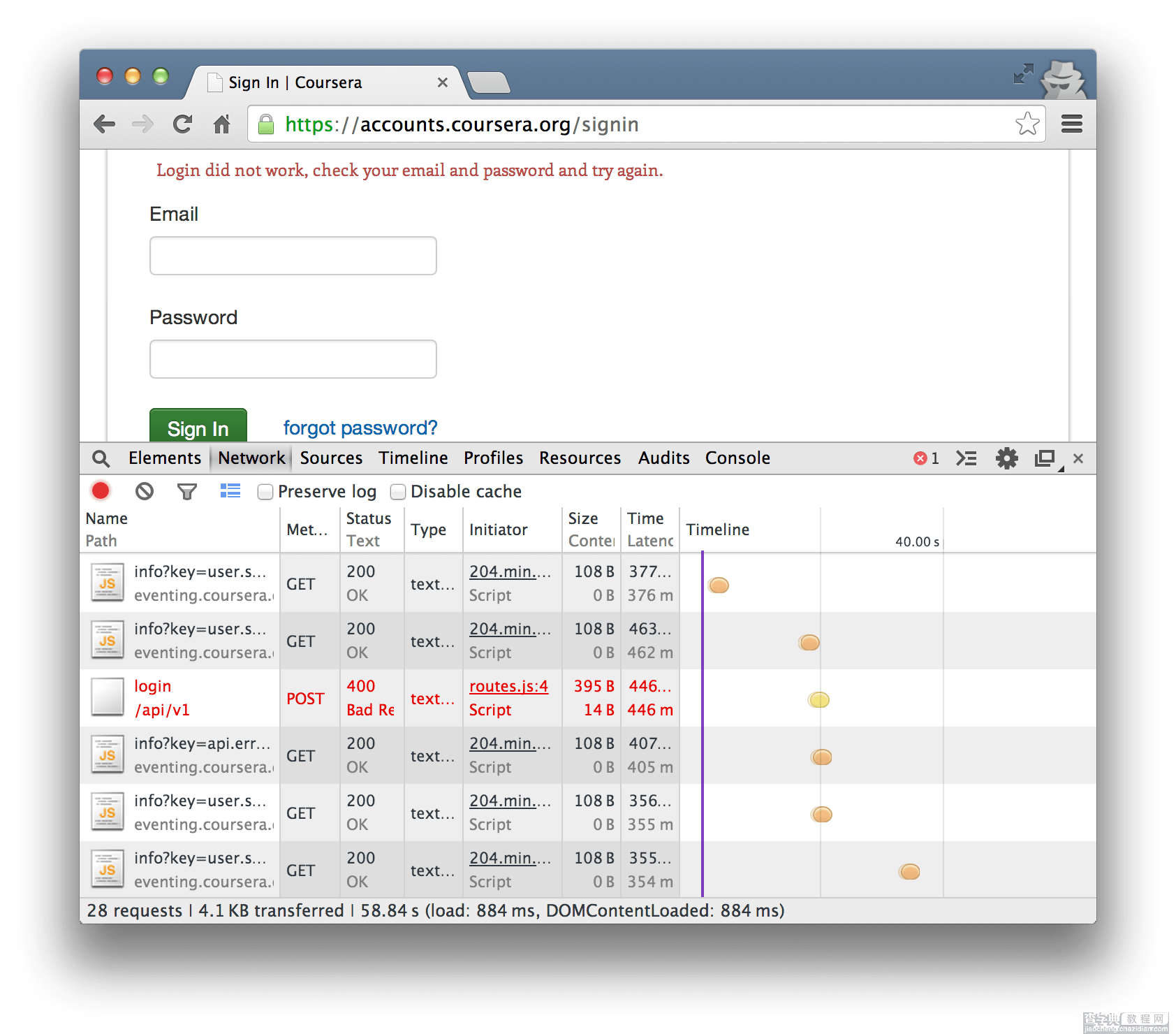
地址为:https://accounts.coursera.org/api/v1/login。为了知道向服务器提交了哪些内容,进一步观察post页面中表单中内容,如下图:
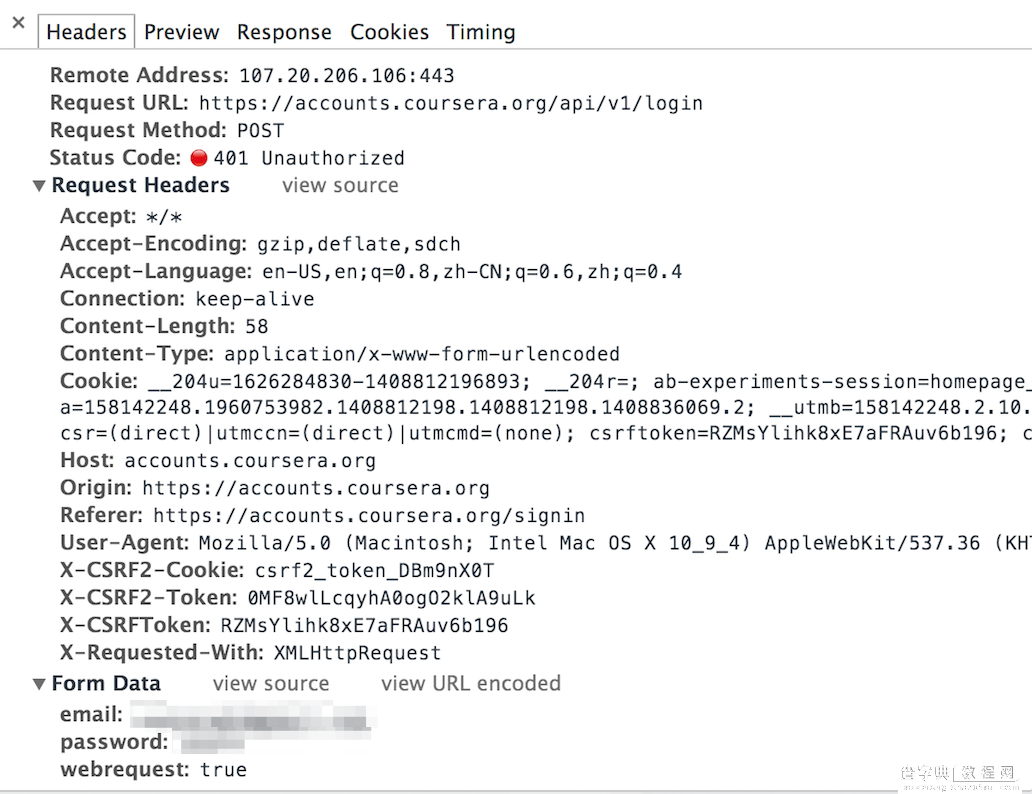
我们看到一共有三个字段:
email:账号的注册邮箱password:账号密码webrequest:附加的字段,值为true。
接下来就动手写吧,我选择用python的Requests库来模拟登录,关于Requests官网是这样介绍的。
Requests is an elegant and simple HTTP library for Python, built for human beings.
事实上requests用起来确实简单方便,不亏是专门为人类设计的http库。requests提供了Session对象,可以用来在不同的请求中传递一些相同的数据,比如在每次请求中都携带cookie。
初步的代码如下:
signin_url = "https://accounts.coursera.org/api/v1/login"
logininfo = {"email": "...",
"password": "...",
"webrequest": "true"
}
user_agent = ("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_4) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/36.0.1985.143 Safari/537.36")
post_headers = {"User-Agent": user_agent,
"Referer": "https://accounts.coursera.org/signin"
}
coursera_session = requests.Session()
login_res = coursera_session.post(signin_url,
data=logininfo,
headers=post_headers,
)
if login_res.status_code == 200:
print "Login Successfully!"
else:
print login_res.text
将表单中提交的内容存放在字典中,然后作为data参数传递给Session.post函数。一般情况下,最好是加上请求User-Agent,Referer等请求头部,User-Agent用来模拟浏览器请求,Referer用来告诉服务器我是从referer页面跳转到请求页面的,有时候服务器会检查请求的Referer字段来保证是从固定地址跳到当前请求页的。
上面片段的运行结果很奇怪,显示如下信息:Invalid CSRF Token。后来在github上面搜索到一个Coursera的批量下载脚本,发现人家发送页面请求时headers多了XCSRF2Cookie, XCSRF2Token, XCSRFToken, cookie4个字段。于是又重新看了一下post页面的请求头部,发现确实有这几个字段,估计是服务器端用来做一些限制的。
用浏览器登录了几次,发现XCSRF2Token, XCSRFToken是长度为24的随机字符串,XCSRF2Cookie为"csrf2_token_"加上长度为8的随机字符串。不过一直没搞明白Cookie是怎么求出来的,不过看github上面代码,Cookie似乎只是"csrftoken"和其他三个的组合,试了一下竟然可以。
在原来的代码上添加以下部分就足够了。
def randomString(length):
return ''.join(random.choice(string.letters + string.digits) for i in xrange(length))
XCSRF2Cookie = 'csrf2_token_%s' % ''.join(randomString(8))
XCSRF2Token = ''.join(randomString(24))
XCSRFToken = ''.join(randomString(24))
cookie = "csrftoken=%s; %s=%s" % (XCSRFToken, XCSRF2Cookie, XCSRF2Token)
post_headers = {"User-Agent": user_agent,
"Referer": "https://accounts.coursera.org/signin",
"X-Requested-With": "XMLHttpRequest",
"X-CSRF2-Cookie": XCSRF2Cookie,
"X-CSRF2-Token": XCSRF2Token,
"X-CSRFToken": XCSRFToken,
"Cookie": cookie
}
至此登录功能初步实现。
分析资源链接
登录成功后,我们只需要get到资源页面的内容,然后过滤出自己需要的资源链接就行了。资源页面的地址很简单,为https://class.coursera.org/name/lecture,其中name为课程名称。比如对于课程comnetworks-002,资源页面地址为https://class.coursera.org/comnetworks-002/lecture。
抓取到页面资源后,我们需要分析html文件,这里选择使用BeautifulSoup。BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库,相当强大。具体使用官网上有很详细的文档,这里不再赘述。在使用BeautifulSoup前,我们还得找出资源链接的规律,方便我们过滤。
其中课程每周的总题目为class=course-item-list-header的div标签下,每周的课程均在class=course-item-list-section-list的ul标签下,每节课程在一个li标签中,课程资源则在li标签中的div标签中。
查看了几门课程之后,发现过滤资源链接的方法很简单,如下:
ppt和ppt资源:用正则表达式匹配链接;字幕资源:找到title="Subtitles (srt)"的标签,取其href属性;视频资源:找到title="Video (MP4)"的标签,取其href属性即可。
字幕和视频也可以用正则表达式过滤,不过用BeautifulSoup根据title属性来匹配,有更好的易读性。而ppt和pdf资源,没有固定的title属性,只好利用正则表达式来匹配。
具体代码如下:
soup = BeautifulSoup(content)
chapter_list = soup.find_all("div", class_="course-item-list-header")
lecture_resource_list = soup.find_all("ul", class_="course-item-list-section-list")
ppt_pattern = re.compile(r'https://[^"]*.ppt[x]?')
pdf_pattern = re.compile(r'https://[^"]*.pdf')
for lecture_item, chapter_item in zip(lecture_resource_list, chapter_list):
# weekly title
chapter = chapter_item.h3.text.lstrip()
for lecture in lecture_item:
lecture_name = lecture.a.string.lstrip()
# get resource link
ppt_tag = lecture.find(href=ppt_pattern)
pdf_tag = lecture.find(href=pdf_pattern)
srt_tag = lecture.find(title="Subtitles (srt)")
mp4_tag = lecture.find(title="Video (MP4)")
print ppt_tag["href"], pdf_tag["href"]
print srt_tag["href"], mp4_tag["href"]
下载资源
既然已经得到了资源链接,下载部分就很容易了,这里我选择使用curl来下载。具体思路很简单,就是输出curl resource_link -o file_name到一个种子文件中去,比如到feed.sh中。这样只需要给种子文件执行权限,然后运行种子文件即可。
为了便于归类课程资源,可以为课程每周的标题建立一个文件夹,之后该周的所有课程均下载在该目录下。为了方便我们快速定位到每节课的所有资源,可以把一节课的所有资源文件均命名为课名.文件类型。具体的实现比较简单,这里不再给出具体程序了。可以看一下一个测试例子中的feed.sh文件,部分内容如下:
mkdir 'Week 1: Introduction, Protocols, and Layering'
cd 'Week 1: Introduction, Protocols, and Layering'
curl https://d396qusza40orc.cloudfront.net/comnetworks/lect/1-readings.pdf -o '1-1 Goals and Motivation (15:46).pdf'
curl https://class.coursera.org/comnetworks-002/lecture/subtitles?q=25_en&format=srt -o '1-1 Goals and Motivation (15:46).srt'
curl https://class.coursera.org/comnetworks-002/lecture/download.mp4?lecture_id=25 -o '1-1 Goals and Motivation (15:46).mp4'
curl https://d396qusza40orc.cloudfront.net/comnetworks/lect/1-readings.pdf -o '1-2 Uses of Networks (17:12).pdf'
curl https://class.coursera.org/comnetworks-002/lecture/subtitles?q=11_en&format=srt -o '1-2 Uses of Networks (17:12).srt'
curl https://class.coursera.org/comnetworks-002/lecture/download.mp4?lecture_id=11 -o '1-2 Uses of Networks (17:12).mp4'
到这里为止,我们已经成功完成爬取Coursera课程资源的目标,具体的代码放在gist上。使用时,我们只需要运行程序,并把课程名称作为参数传递给程序就可以了(这里的课程名称并不是整个课程的完整名字,而是在课程介绍页面地址中的缩略名字,比如Computer Networks这门课,课程名称是comnetworks-002)。
其实,这个程序可以看做一个简单的小爬虫程序了,下面粗略介绍下爬虫的概念。
一点都不简单的爬虫
关于什么是爬虫,wiki上是这样说的
A Web crawler is an Internet bot that systematically browses the World Wide Web, typically for the purpose of Web indexing.
爬虫的总体架构图如下(图片来自wiki):
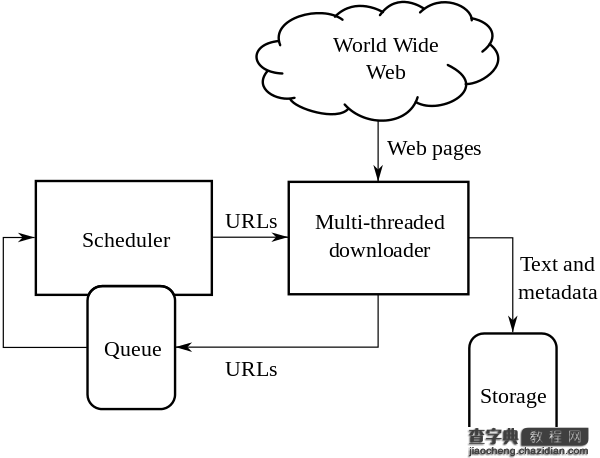
简单来说,爬虫从Scheduler中获取初始的urls,下载相应的页面,存储有用的数据,同时分析该页面中的链接,如果已经访问就pass,没访问的话加入到Scheduler中等待抓取页面。
当然有一些协议来约束爬虫的行为规范,比如许多网站都有一个robots.txt文件来规定网站哪些内容可以被爬取,哪些不可以。
每个搜索引擎背后都有一个强大的爬虫程序,把触角伸到网络中的所有角落,不断去收集有用信息,并建立索引。这种搜索引擎级别的爬虫实现起来非常复杂,因为网络上的页面数量太过庞大,只是遍历他们就已经很困难了,更不要说去分析页面信息,并建立索引了。
实际应用中,我们只需要爬取特定站点,抓取少量的资源,这样实现起来简单很多。不过仍然有许多让人头疼的问题,比如许多页面元素是javascript生成的,这时候我们需要一个javascript引擎,渲染出整个页面,再加以过滤。
更糟糕的是,许多站点都会用一些措施来阻止爬虫爬取资源,比如限定同一IP一段时间的访问次数,或者是限制两次操作的时间间隔,加入验证码等等。绝大多数情况下,我们不知道服务器端是如何防止爬虫的,所以要想让爬虫工作起来确实挺难的。