

先来看下反引号可以成功执行命名的代码片段。代码如下:
复制代码 代码如下:
`ls -al`;
`ls -al`;
echo "sss"; `ls -al`;
$sql = "SELECT `username` FROM `table` WHERE 1";
$sql = 'SELECT `username` FROM `table` WHERE 1'
/*
无非是 前面有空白字符,或者在一行代码的结束之后,后面接着写,下面两行为意外情况,也就是SQL命令里的反引号,要排除的就是它。
*/
正则表达式该如何写?
分析:
对于可移植性的部分共同点是什么?与其他正常的包含反引号的部分,区别是什么?
他们前面可以有空格,tab键等空白字符。也可以有程序代码,前提是如果有引号(单双)必须是闭合的。才是危险有隐患的。遂CFC4N给出的正则如下:【(?:(?:^(?:s+)?)|(?:(?P<quote>["'])[^(?P=quote)]+?(?P=quote)[^`]*?))`(?P<shell>[^`]+)`】。
解释一下:
【(?:(?:^(?:s+)?)|(?:(?P<quote>["'])[^(?P=quote)]+?(?P=quote)[^`]*?))】
匹配开始位置或者开始位置之后有空白字符或者前面有代码,且代码有闭合的单双引号。(这段PYTHON的正则中用了捕获命名以及反向引用)
【`(?P<shell>[^`]+)`】这个就比较简单了,匹配反引号中间的字符串。
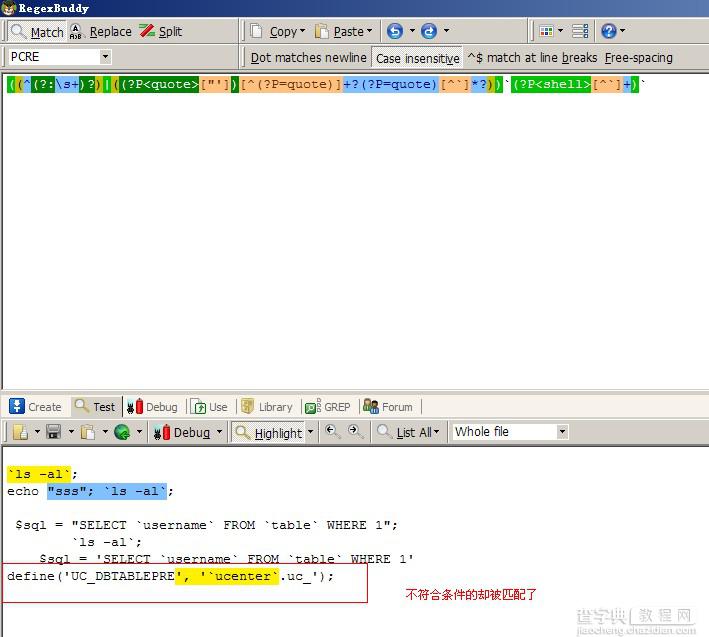
某检测PHP webshell的python脚本考虑欠佳。
再看看下一个列表的第一个元素。【(system|shell_exec|exec|popen)】,这个正则的意思是只要字符串里包含“system”、“shell_exec”、“exec”、“popen”这四组字符串即判定为危险字符。很明显,这个方法太不严谨。如果程序员写的代码中,包含了这四组字符,即可被判定为危险函数。很不准确,误报率极高。见下图
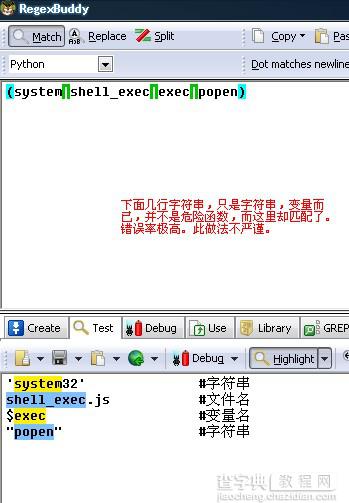
某检测PHP webshell的python脚本考虑欠佳。
到底什么样的代码是可疑的代码?关键词是什么?
可疑的代码肯定是由可以执行危险操作的函数构成,可以执行危险操作的PHP函数最重要的就是“eval”函数了,对于加密的PHP代码(仅变形字符串,非zend等方式加密),肯定要用到“eval”函数,所以,对于不管是用哪种加密方法的代码,肯定要用到“eval”函数。其次就是可以执行系统命令的函数了,比如上面某牛的代码中提到的四个“system”、“shell_exec”、“exec”、“popen”。当然还有其他的,比如passthru等。PHP还支持“·”字符(ESC键下面那个)直接执行系统命令。我们可以把正则写成这样【b(?P<function>eval|proc_open|popen|shell_exec|exec|passthru|system)bs*(】。
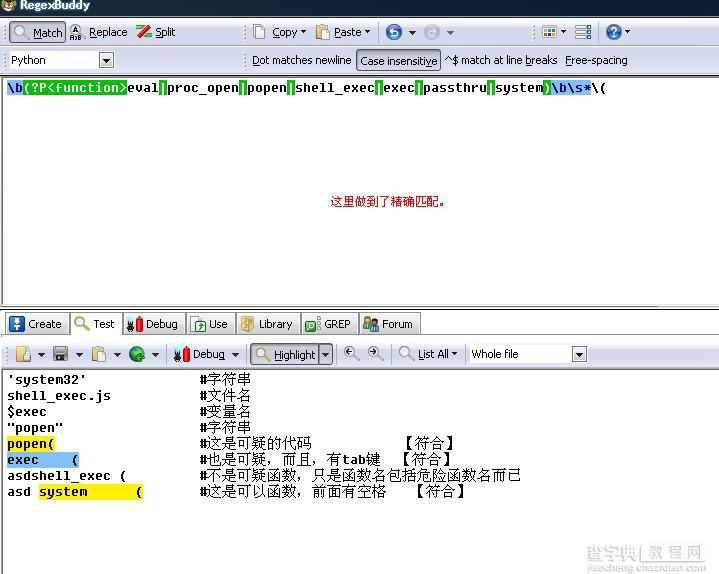
检测PHP webshell的python脚本相对较为严谨的匹配
解释一下:
大家都知道【bb】用来匹配单词两边的位置的。要保证【bb】中间的是单词,即使函数名前面加特殊字符,也一样通过匹配,比如加@来屏蔽错误。后面的【s*】用来匹配空白字符的,包括空格,tab键,次数为0到无数次。前面的【(?P)】是捕获命名组。用来当作python代码直接引用匹配结果的key。
还有的网友提到了,如果我把代码放到图片拓展名的文件里呢?那你只检测.php,.inc的文件,还是找不到我的呀。嗯,是的,如果恶意代码在gif、jpg、png、aaa等乱七八糟的拓展名文件里,是不能被apache、IIS等web Services解析的,必须通过include/require(_once)来引入。那么,我们只要匹配include/require(_once)后面的文件名是不是常规的“.php”、“.inc”文件。如果不是,则为可疑文件。正则如下【(?P<function>b(?:include|require)(?:_once)?b)s*(?s*["'](?P<filename>.*?(?<!.(?:php|inc)))["']】。
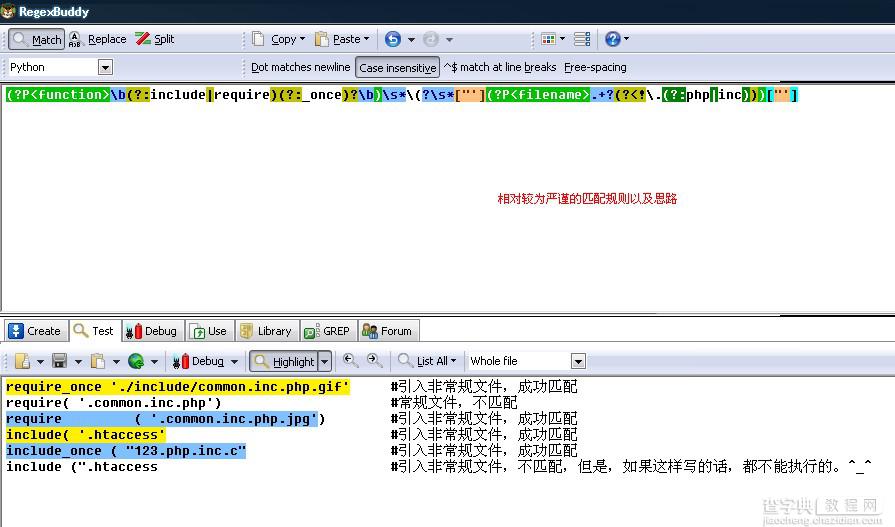
检测PHP WEBSHELL的python脚本较为严谨做法
解释一下:
先看【(?P<function>b(?:include|require)(?:_once)?b)】,【(?P<name>)】为正则表达式的“命名捕获”,PHP中有同样的用法。也就是说,在这括号内的捕获的数据,会分配到结果数组的key为“name”的value中。再看里面的【b(?:include|require)(?:_once)?b】,【bb】不解释了,为单词边界位置。里面的【(?:include|require)】匹配字符串“include”、“require”两个单词,其中前面的【(?:)】未不分配组,用于提高效率,可以去掉【?:】变成【(include|require)】。在后面一个【(?:_once)】也是做不分配组的操作,便于提高正则表达式效率。同样,后面的量词是“?”代表这个组可有可无。就满足了“include”、“include_once”、“require”、“require_once”四种情况。有的朋友可能这样写【(include|include_once|require|require_once)】也能实现目的。但是,为了更搞的效率,我们对这个正则做优化,针对部分字符串做分支更改,改成上面那个【b(?:include|require)(?:_once)?b】。
再看下面的【s*(?s*["'](?P<filename>.+?(?<!.(?:php|inc)))["']】中,【s*】匹配空白字符,包括空格,tab键等。后面的【(?】,匹配字符“(”,后面的量词“?”表示这半个小酷括号可有可无。防止“incude “123.php””这种没有括号的情况。再后面【["']】匹配双引号,单引号的。最后的也是。再看看这个【(?P<filename>.+?(?<!.(?:php|inc)))】,其中【(?P<filename>)】上面介绍了,为命名捕获,把结果放到match.group(“filename”)里。【.*?】为任意字符,后面的量词是“忽略优先量词”,也就是平常说的“非贪婪”。这里最少匹配零个,(防止.aa、.htaccess这种没有文件名,只有文件拓展名的文件被引入)。后面的【(?<!.(?:php|inc))】,这里用到了反向零宽断言(环视)的非操作(只匹配位置,不匹配字符串,跟【^$b】等一样)。这个表达式是针对这个位置的后面字符起作用的,也就是说后面的【["']】的前面不能是“.php”、“.inc”,这里也就是取了文件名的最后的拓展名。(正则里,可以用【^】对字符取非,但是不能对“字符串组”取非,这里用了零宽断言来实现。)
综上所述,最后,鄙人给出的python代码如下:
复制代码 代码如下:
#!/usr/bin/python
#-*- encoding:UTF-8 -*-
###
## @package
##
## @author CFC4N <cfc4nphp@gmail.com>
## @copyright copyright (c) Www.cnxct.Com
## @Version $Id: check_php_shell.py 37 2010-07-22 09:56:28Z cfc4n $
###
import os
import sys
import re
import time
def listdir(dirs,liston='0'):
flog = open(os.getcwd()+"/check_php_shell.log","a+")
if not os.path.isdir(dirs):
print "directory %s is not exist"% (dirs)
return
lists = os.listdir(dirs)
for list in lists:
filepath = os.path.join(dirs,list)
if os.path.isdir(filepath):
if liston == '1':
listdir(filepath,'1')
elif os.path.isfile(filepath):
filename = os.path.basename(filepath)
if re.search(r".(?:php|inc|html?)$", filename, re.IGNORECASE):
i = 0
iname = 0
f = open(filepath)
while f:
file_contents = f.readline()
if not file_contents:
break
i += 1
match = re.search(r'''(?P<function>b(?:include|require)(?:_once)?b)s*(?s*["'](?P<filename>.*?(?<!.(?:php|inc)))["']''', file_contents, re.IGNORECASE| re.MULTILINE)
if match:
function = match.group("function")
filename = match.group("filename")
if iname == 0:
info = 'n[%s] :n'% (filepath)
else:
info = ''
info += 't|-- [%s] - [%s] line [%d] n'% (function,filename,i)
flog.write(info)
print info
iname += 1
match = re.search(r'b(?P<function>eval|proc_open|popen|shell_exec|exec|passthru|system)bs*(', file_contents, re.IGNORECASE| re.MULTILINE)
if match:
function = match.group("function")
if iname == 0:
info = 'n[%s] :n'% (filepath)
else:
info = ''
info += 't|-- [%s] line [%d] n'% (function,i)
flog.write(info)
print info
iname += 1
f.close()
flog.close()
if '__main__' == __name__:
argvnum = len(sys.argv)
liston = '0'
if argvnum == 1:
action = os.path.basename(sys.argv[0])
print "Command is like:n %s D:wwwroot n %s D:wwwroot 1 -- recurse subfolders"% (action,action)
quit()
elif argvnum == 2:
path = os.path.realpath(sys.argv[1])
listdir(path,liston)
else:
liston = sys.argv[2]
path = os.path.realpath(sys.argv[1])
listdir(path,liston)
flog = open(os.getcwd()+"/check_php_shell.log","a+")
ISOTIMEFORMAT='%Y-%m-%d %X'
now_time = time.strftime(ISOTIMEFORMAT,time.localtime())
flog.write("n----------------------%s checked ---------------------n"% (now_time))
flog.close()
## 最新代码在文章结尾的链接里给出了。2010/07/31 更新。
仅供参考,欢迎斧正。
下面截图为扫描Discuz7.2的效果图,当然,也有误报。相对网上流传的python脚本,误报更少,更精确了。 
检测PHP WEBSHELL的python脚本的检测结果
问:这个方法完美了吗?可以查找目前已知的所有危险函数文件了吗?
答:不能,如果include等引入的文件没有拓展名,这里就匹配不到了。
问:如何解决?
答:留给你解决,聪明的你,肯定可以搞定。
PS:“`”反引号 执行命令的还没写,暂时没好的办法。容易跟SQL语句中的反引号混淆。不太好匹配。如果光匹配反引号就提示的话,那误报太大了。待定吧。(术业有专攻,请勿因为一处不好的代码,否定一个人的能力。你懂的。再次重申,此文只针对代码,不针对人。其次,鄙人给出的python代码随便复制,随便传播,爱留版权就留版权,不爱留就删了相关字符,也就是您爱干吗干吗。)
我先休息一会,明天再说。(前半句为三国杀曹仁的台词,哈。)