

C语言字符输入与输出
标准库提供的输入/输出模型非常简单。无论文本从何处输入,输出到何处,其输入/输出都是按照字符流的方式处理。文本流是由多行字符构成的字符序列,而每行字符则由 0 个或多个字符组成,行末是一个换行符。标准库负责使每个输入/输出流都能够遵守这一模型。使用标准库的 C 语言程序员不必关心在程序之外这些行是如何表示的。
标准库提供了一次读/写一个字符的函数,其中最简单的是 getchar 和 putchar 两个函数。每次调用时,getchar 函数从文本流中读入下一个输入字符,并将其作为结果值返回。也就是说,在执行语句
c = getchar()
之后,变量 c 中将包含输入流中的下一个字符。这种字符通常是通过键盘输入的。
每次调用 putchar 函数时将打印一个字符。例如,语句
putchar()
将把整型变量 c 的内容以字符的形式打印出来,通常是显示在屏幕上。putchar 与 printf 这两个函数可以交替调用,输出的次序与调用的次序一致。
借助于 getchar 与 putchar 函数,可以在不了解其它输入/输出知识的情况下编写出数量惊人的有用的代码。最简单的例子就是把输入一次一个字符地复制到输出,其基本思想如下:
读一个字符
while(该字符不是文件结束指示符)
输出刚读入的字符
读下一个字符
将上述基本思想转换为 C 语言程序为:
#include <stdio.h> /* copy input to output; 1st version*/ main() { int c; c = getchar(); while (c != EOF) { putchar(c); c = getchar(); } }
其中,关系运算符!=表示“不等于”。
字符在键盘、屏幕或其它的任何地方无论以什么形式表现,它在机器内部都是以位模式存储的。char 类型专门用于存储这种字符型数据,当然任何整型(int)也可以用于存储字符型数据。因为某些潜在的重要原因,我们在此使用 int 类型。
这里需要解决如何区分文件中有效数据与输入结束符的问题。C 语言采取的解决方法是:在没有输入时,getchar 函数将返回一个特殊值,这个特殊值与任何实际字符都不同。这个值称为 EOF(end of file,文件结束)。我们在声明变量 c 的时候,必须让它大到足以存放 getchar 函数返回的任何值。这里之所以不把 c 声明成 char 类型,是因为它必须足够大,除了能存储任何可能的字符外还要能存储文件结束符 EOF。因此,我们将 c 声明成 int 类型。
EOF 定义在头文件<stdio.h>中,是个整型数,其具体数值是什么并不重要,只要它与任何 char 类型的值都不相同即可。这里使用符号常量,可以确保程序不需要依赖于其对应的任何特定的数值。
对于经验比较丰富的 C 语言程序员,可以把这个字符复制程序编写得更精炼一些。在 C 语言中,类似于
c = getchar()
之类的赋值操作是一个表达式,并且具有一个值,即赋值后左边变量保存的值。也就是说,赋值可以作为更大的表达式的一部分出现。如果将为 c 赋值的操作放在 while 循环语句的测试部分中,上述字符复制程序便可以改写成下列形式:
#include <stdio.h> /* copy input to output; 2nd version */ main() { int c; while ((c = getchar()) != EOF) putchar(c); }
在该程序中,while 循环语句首先读一个字符并将其赋值给 c,然后测试该字符是否为文件结束标志。如果该字符不是文件结束标志,则执行 while 语句体,并打印该字符。随后重复执行 while 语句。当到达输入的结尾位置时,while 循环语句终止执行,从而整个 main 函数执行结束。
以上这段程序将输入集中化,getchar 函数在程序中只出现了一次,这样就缩短了程序,整个程序看起来更紧凑。习惯这种风格后,读者就会发现按照这种方式编写的程序更易阅读。我们经常会看到这种风格。(不过,如果我们过多地使用这种类型的复杂语句,编写的程序可能会很难理解,应尽量避免这种情况。)
对 while 语句的条件部分来说,赋值表达式两边的圆括号不能省略。不等于运算符!=的优先级比赋值运算符=的优先级要高,这样,在不使用圆括号的情况下关系测试!=将在赋值=操作之前执行。因此语句
c = getchar() != EOF
等价于语句
c = (getchar() != EOF)
该语句执行后,c 的值将被置为 0 或 1(取决于调用 getchar 函数时是否碰到文件结束标志),这并不是我们所希望的结果。
计算字符个数
下列程序用于对字符进行计数:
#include <stdio.h> /* 统计输入的字符数 Version 1.0 */ main() { long nc; nc = 0; while(getchar() != EOF) ++nc; printf("%ldn", nc); }
其中,语句 ++nc; 引入了一个新的运算符++,其功能是执行加 1 操作。可以用语句 nc = nc + 1 代替它,但语句++nc 更精炼一些,且通常效率也更高。与该运算符相应的是自减运算符--。++与--这两个运算符既可以作为前缀运算符(如++nc),也可以作为后缀运算符(如 nc++)。我们在后面将看到,这两种形式在表达式中具有不同的值,但++nc 与 nc++都使 nc 的值增加 1。目前,我们只使用前缀形式。
该字符计数程序使用 long 类型的变量存放计数值,而没有使用 int 类型的变量。long整型数(长整型)至少要占用 32 位存储单元。在某些机器上 int 与 long 类型的长度相同,但在一些机器上,int 类型的值可能只有 16 位存储单元的长度(最大值为 32767),这样,相当小的输入都可能使 int 类型的计数变量溢出。转换说明%ld 告诉 printf 函数其对应的参数是 long 整型。
使用 double(双精度浮点数)类型可以处理更大的数字。我们在这里不使用 while 循环语句,而用 for 循环语句来展示编写此循环的另一种方法:
#include <stdio.h> /* count characters in input; 2nd version */ main() { double nc; for (nc = 0; getchar() != EOF; ++nc) ; printf("%.0fn", nc); }
对于 float 与 double 类型。printf 函数都使用%f 进行说明。%.0f 强制不打印小数点和小数部分,因此小数部分的位数为 0。
在该程序段中,for 循环语句的循环体是空的,这是因为所有工作都在测试(条件)部分与增加步长部分完成了。但 C 语言的语法规则要求 for 循环语句必须有一个循环体,因此用单独的分号代替。单独的分号称为空语句,它正好能满足 for 语句的这一要求。把它单独放在一行是为了更加醒目。
在结束讨论字符计数程序之前,我们考虑以下情况:如果输入中不包含字符,那么,在第一次调用 getchar 函数的叫候,while 语句或 for 语句中的条件测试从一开始就为假,程序的执行结果将为 0,这也是正确的结果。这一点很重要。whi1e 语句与 for 语句的优点之一就是在执行循环体之前就对条件进行测试,如果条件不满足,则不执行循环体,这就可能出现循环体一次都不执行的情况。在出现 0 长度的输入时,程序的处理应该灵活一些,在出现边界条件时,while 语句与 for 语句有助于确保程序执行合理的操作。
连接两个字符串的程序:
#include <stdio.h> #include <string.h> void main() { int i; char str1[30]="welcome to "; char str2[]= "www.nowamagic.net"; printf("%sn",strcat(str1,str2)); scanf("%d", &i); }
在MFC下实现计算字符串的程序:
void CNowaMagic_MFCDlg::OnBnClickedOk() { // TODO: 在此添加控件通知处理程序代码 //CDialogEx::OnOK(); //获得EDIT CEdit* pBoxOne; pBoxOne = (CEdit*) GetDlgItem(IDC_EDIT1); CString str; CString sStrLen; char tmp[10] = ""; pBoxOne-> GetWindowText(str); int nStrLen = str.GetLength(); sStrLen = itoa(nStrLen,tmp,10); CString str2 = _T("字符数为:"); MessageBox(str2 + sStrLen,_T("程序运行结果"),MB_OK); str.ReleaseBuffer(); }
程序运行结果如下:
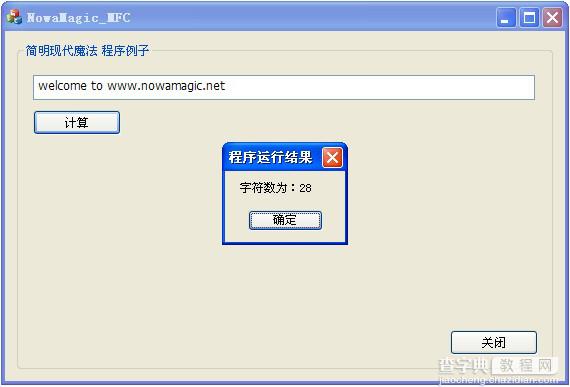
为了更好地进行程序实践,推荐使用在MFC上也把程序实践一遍,有UI出来乐趣会更大。
一些细节如下:
定义 char tmp[10] = ""; 时如果不指定数组长度会造成内存越界。
用 str.GetLength(); 方法获取 CString 的长度。
itoa(int,str,10) 可以将整数转换成字符串。int 就是要转的整数,str是存放转后的字符串,10是模式(还有其他模式)。
连接两个 CString 可以直接用 + 操作符。