

c语言标准
1978年,丹尼斯·里奇(Dennis Ritchie)和Brian Kernighan合作出版了《C程序设计语言》的第一版。书中介绍的C语言标准也被C语言程序设计师称作“K&R C”,第二版的书中也包含了一些ANSI C的标准。K&R C主要介绍了以下特色:
结构(struct)类型
长整数(long int)类型
无符号整数(unsigned int)类型
把运算符=+和=-改为+=和-=。因为=+和=-会使得编译器不知道用户要处理i = +10还是i =- 10,使得处理上产生混淆。
即使在后来ANSI C标准被提出的许多年后,K&R C仍然是许多编译器的最低标准要求,许多老旧的编译仍然运行K&R C的标准。
C89
1989年,C语言被 ANSI 标准化(ANSI X3.159-1989)。标准化的一个目的是扩展K&R C。这个标准包括了一些新特性。在K&R出版后,一些新特性被非官方地加到C语言中。
void 函数
函数返回 struct 或 union 类型
void * 数据类型
在 ANSI标准化自己的过程中,一些新的特性被加了进去。ANSI也规定一套了标准函数库。ANSI ISO(国际标准化组织)成立 ISO/IEC JTC1/SC22/WG14 工作组,来规定国际标准的C语言。通过对ANSI标准的少量修改,最终通过了 ISO 9899:1990。随后,ISO标准被 ANSI 采纳。
传统C语言到ANSI/ISO标准C语言的改进包括:
增加了真正的标准库
新的预处理命令与特性
函数原型允许在函数申明中指定参数类型
一些新的关键字,包括 const、volatile 与 signed
宽字符、宽字符串与字节多字符
对约定规则、声明和类型检查的许多小改动与澄清
WG14工作小组之后又于1995年,对1985年颁布的标准做了两处技术修订(缺陷修复)和一个补充(扩展)。下面是 1995 年做出的所有修改:
3 个新的标准库头文件 iso646.h、wctype.h 和 wchar.h
几个新的记号与预定义宏,用于对国际化提供更好的支持
printf/sprintf 函数一系列新的格式代码
大量的函数和一些类型与常量,用于多字节字符和宽字节字符
C99
在 ANSI的标准确立后,C语言的规范在一段时间内没有大的变动,然而C++在自己的标准化建立过程中继续发展壮大。《标准修正案一》在1995年为C语言 建立了一个新标准,但是只修正了一些C89标准中的细节和增加更多更广得国际字符集支持。不过,这个标准引出了1999年ISO 9899:1999的发表。它通常被成为C99。C99被ANSI于2000年3月采用。
在C99中包括的特性有:
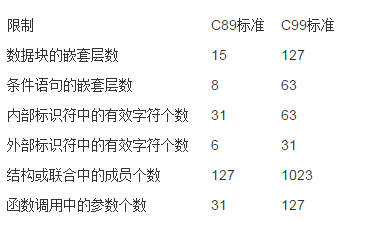
对编译器限制增加了,比如源程序每行要求至少支持到 4095 字节,变量名函数名的要求支持到 63 字节(extern 要求支持到 31)
预处理增强了。例如:
宏支持取可变参数 #define Macro(...) __VA_ARGS__
使用宏的时候,参数如果不写,宏里用 #,## 这样的东西会扩展成空串。(以前会出错的)
支持 // 行注释(这个特性实际上在C89的很多编译器上已经被支持了)
增加了新关键字 restrict, inline, _Complex, _Imaginary, _Bool
支持 long long, long double _Complex, float _Complex 这样的类型
支持 <: :> <% %> %: %:%: ,等等奇怪的符号替代,D&E 里提过这个
支持了不定长的数组。数组的长度就可以用变量了。声明类型的时候呢,就用 int a[*] 这样的写法。不过考虑到效率和实现,这玩意并不是一个新类型。所以就不能用在全局里,或者 struct union 里面,如果你用了这样的东西,goto 语句就受限制了。
变量声明不必放在语句块的开头,for 语句提倡这么写 for(int i=0;i<100;++i) 就是说,int i 的声明放在里面,i 只在 for 里面有效。
当一个类似结构的东西需要临时构造的时候,可以用(type_name){xx,xx,xx} 这有点像 C++ 的构造函数
初始化结构的时候现在可以这样写:
struct {int a[3],b;} hehe[] = { [0].a = {1}, [1].a = 2 };
struct {int a, b, c, d;} hehe = { .a = 1, .c = 3, 4, .b = 5} // 3,4 是对 .c,.d 赋值的
字符串里面,/u 支持 unicode 的字符
支持 16 进制的浮点数的描述
所以 printf scanf 的格式化串多支持了 ll / LL(VC6 里用的 I64)对应新的 long long 类型。
浮点数的内部数据描述支持了新标准,这个可以用 #pragma 编译器指定
除了已经有的 __line__ __file__ 以外,又支持了一个 __func__ 可以得到当前的函数名
对于非常数的表达式,也允许编译器做化简
修改了对于/% 处理负数上的定义,比如老的标准里 -22 / 7 = -3, -22 % 7 = -1 而现在 -22 / 7 = -4, -22 % 7 = 6
取消了不写函数返回类型默认就是 int 的规定
允许 struct 定义的最后一个数组写做 [] 不指定其长度描述
const const int i;将被当作 const int i;处理
增 加和修改了一些标准头文件,比如定义 bool 的 <stdbool.h> 定义一些标准长度的 int 的 <inttypes.h> 定义复数的 <complex.h> 定义宽字符的 <wctype.h> 有点泛型味道的数学函数 <tgmath.h> 跟浮点数有关的 <fenv.h>。<stdarg.h> 里多了一个 va_copy 可以复制 ... 的参数。<time.h> 里多了个 struct tmx 对 struct tm 做了扩展
输入输出对宽字符还有长整数等做了相应的支持
相对于c89的变化还有
1、增加restrict指针
C99中增加了公适用于指针的restrict类型修饰符,它是初始访问指针所指对象的惟一途径,因此只有借助restrict指针表达式才能 访问对象。restrict指针指针主要用做函数变元,或者指向由malloc()函数所分配的内存变量。restrict数据类型不改变程序的语义。
如果某个函数定义了两个restrict指针变元,编译程序就假定它们指向两个不同的对象,memcpy()函数就是restrict指针的一个典型应用示例。C89中memcpy()函数原型如下:
代码: void *memcpy (void *s1, const void *s2, size_t size);
如果s1和s2所指向的对象重叠,其操作就是未定义的。memcpy()函数只能用于不重叠的对象。C99中memcpy()函数原型如下:代 码: void *memcpy(void *restrict s1, const void *restrict s2,size_t size);
通过使用restrict修饰s1和s2 变元,可确保它们在该原型中指向不同的对象。
2、inline(内联)关键字
内联函数除了保持结构化和函数式的定义方式外,还能使程序员写出高效率的代码。函数的每次调用与返回都会消耗相当大的系统资源,尤其是当函数调 用发生在重复次数很多的循环语句中时。一般情况下,当发生一次函数调用时,变元需要进栈,各种寄存器内存需要保存。当函数返回时,寄存器的内容需要恢复。 如果该函数在代码内进行联机扩展,当代码执行时,这些保存和恢复操作旅游活动会再发生,而且函数调用的执行速度也会大大加快。函数的联机扩展会产生较长的 代码,所以只应该内联对应用程序性能有显著影响的函数以及长度较短的函数。
3、新增数据类型
_Bool
值是0或1。C99中增加了用来定义bool、true以及false宏的头文件夹<stdbool.h>,以便程序员能够编写同时兼容于C与C++的应用程序。在编写新的应用程序时,应该使用
<stdbool.h>头文件中的bool宏。
_Complex and _Imaginary
C99标准中定义的复数类型如下:float_Complex;float_Imaginary;double_Complex;double_Imaginary;long double_Complex;long double_Imaginary。
<complex.h>头文件中定义了complex和imaginary宏,并将它们扩展为_Complex和 _Imaginary,因此在编写新的应用程序时,应该使用<stdbool.h>头文件中的complex和imaginary宏。
long long int
C99标准中引进了long long int(-(2e63 - 1)至2e63 - 1)和unsigned long long int(0 - 2e64 - 1)。long long int能够支持的整数长度为64位。
4、对数组的增强
可变长数组
C99中,程序员声明数组时,数组的维数可以由任一有效的整型表达式确定,包括只在运行时才能确定其值的表达式,这类数组就叫做可变长数组,但是只有局部数组才可以是变长的。
可变长数组的维数在数组生存期内是不变的,也就是说,可变长数组不是动态的。可以变化的只是数组的大小。可以使用*来定义不确定长的可变长数组。
数组声明中的类型修饰符
在C99中,如果需要使用数组作为函数变元,可以在数组声明的方括号内使用static关键字,这相当于告诉编译程序,变元所指向的数组将至少 包含指定的元素个数。也可以在数组声明的方括号内使用restrict,volatile,const关键字,但只用于函数变元。如果使用 restrict,指针是初始访问该对象的惟一途径。如果使用const,指针始终指向同一个数组。使用volatile没有任何意义。
5、单行注释
引入了单行注释标记 "//" , 可以像C++一样使用这种注释了。
6、分散代码与声明
7、预处理程序的修改
a、变元列表
宏可以带变元,在宏定义中用省略号(...)表示。内部预处理标识符__VA_ARGS__决定变元将在何处得到替换。例:#define MySum(...) sum(__VA_ARGS__) 语句MySum(k,m,n);
将被转换成:sum(k, m, n); 变元还可以包含变元。例: #define compare(compf, ...) compf(__VA_ARGS__) 其中的compare(strcmp,"small", "large"); 将替换成:strcmp("small","large");
b、_Pragma运算符
C99引入了在程序中定义编译指令的另外一种方法:_Pragma运算符。格式如下:
_Pragma("directive")
其中directive是要满打满算的编译指令。_Pragma运算符允许编译指令参与宏替换。
c、内部编译指令
STDCFP_CONTRACT ON/OFF/DEFAULT 若为ON,浮点表达式被当做基于硬件方式处理的独立单元。默认值是定义的工具。
STDCFEVN_ACCESS ON/OFF/DEFAULT 告诉编译程序可以访问浮点环境。默认值是定义的工具。
STDC CX_LIMITED_RANGE ON/OFF/DEFAULT 若值为ON,相当于告诉编译程序某程序某些含有复数的公式是可靠的。默认是OFF。
d、新增的内部宏
__STDC_HOSTED__ 若操作系统存在,则为1
__STDC_VERSION__ 199991L或更高。代表C的版本
__STDC_IEC_599__ 若支持IEC 60559浮点运算,则为1
__STDC_IEC_599_COMPLEX__ 若支持IEC 60599复数运算,则为1
__STDC_ISO_10646__ 由编译程序支持,用于说明ISO/IEC 10646标准的年和月格式:yyymmmL
9、复合赋值
C99中,复合赋值中,可以指定对象类型的数组、结构或联合表达式。当使用复合赋值时,应在括弧内指定类型,后跟由花括号围起来的初始化列表;若类型为数组,则不能指定数组的大小。建成的对象是未命名的。
例: double *fp = (double[]) {1.1, 2.2, 3.3};
该语句用于建立一个指向double的指针fp,且该指针指向这个3元素数组的第一个元素。 在文件域内建立的复合赋值只在程序的整个生存期内有效。在模块内建立的复合赋值是局部对象,在退出模块后不再存在。
10、柔性数组结构成员
C99中,结构中的最后一个元素允许是未知大小的数组,这就叫做柔性数组成员,但结构中的柔性数组成员前面必须至少一个其他成员。柔性数组成员 允许结构中包含一个大小可变的数组。sizeof返回的这种结构大小不包括柔性数组的内存。包含柔性数组成员的结构用malloc()函数进行内存的动态 分配,并且分配的内存应该大于结构的大小,以适应柔性数组的预期大小。
11、指定的初始化符
C99中,该特性对经常使用稀疏数组的程序员十分有用。指定的初始化符通常有两种用法:用于数组,以及用于结构和联合。用于数组的格式: = vol; 其中,index表示数组的下标,vol表示本数组元素的初始化值。
例如: int x[10] = {[0] = 10, [5] = 30}; 其中只有x[0]和x[5]得到了初始化。用于结构或联合的格式如下:
member-name(成员名称)
对结构进行指定的初始化时,允许采用简单的方法对结构中的指定成员进行初始化。
例如: struct example{ int k, m, n; } object = {m = 10,n = 200};
其中,没有初始化k。对结构成员进行初始化的顺序没有限制。
12、printf()和scanf()函数系列的增强
C99中printf()和scanf()函数系列引进了处理long long int和unsigned long long int数据类型的特性。long long int 类型的格式修饰符是ll。在printf()和scanf()函数中,ll适用于d,i,o,u和x格式说明符。另外,C99还引进了hh修饰符。当使用 d,i,o,u和x格式说明符时,hh用于指定char型变元。ll和hh修饰符均可以用于n说明符。
格式修饰符a和A用在printf()函数中时,结果将会输出十六进制的浮点数。格式如下:[-]0xh, hhhhp + d 使用A格式修饰符时,x和p必须是大写。A和a格式修饰符也可以用在scanf()函数中,用于读取浮点数。调用printf()函数时,允许在%f说明 符前加上l修饰符,即%lf,但不起作用。
13、C99新增的库
C89中标准的头文件
<assert.h> 定义宏assert()
<ctype.h> 字符处理
<errno.h> 错误报告
<float.h> 定义与实现相关的浮点值
<limits.h> 定义与实现相关的各种极限值
<locale.h> 支持函数setlocale()
<math.h> 数学函数库使用的各种定义
<setjmp.h> 支持非局部跳转
<signal.h> 定义信号值
<stdarg.h> 支持可变长度的变元列表
<stddef.h> 定义常用常数
<stdio.h> 支持文件输入和输出
<stdlib.h> 其他各种声明
<string.h> 支持串函数
<time.h> 支持系统时间函数
C99新增的头文件和库
<complex.h> 支持复数算法
<fenv.h> 给出对浮点状态标记和浮点环境的其他方面的访问
<inttypes.h> 定义标准的、可移植的整型类型集合。也支持处理最大宽度整数的函数
<iso646.h> 首先在此1995年第一次修订时引进,用于定义对应各种运算符的宏
<stdbool.h> 支持布尔数据类型类型。定义宏bool,以便兼容于C++
<stdint.h> 定义标准的、可移植的整型类型集合。该文件包含在<inttypes.h>中
<tgmath.h> 定义一般类型的浮点宏
<wchar.h> 首先在1995年第一次修订时引进,用于支持多字节和宽字节函数
<wctype.h> 首先在1995年第一次修订时引进,用于支持多字节和宽字节分类函数
14、__func__预定义标识符
用于指出__func__所存放的函数名,类似于字符串赋值。
15、其它特性的改动
放宽的转换限制
不再支持隐含式的int规则
删除了隐含式函数声明
对返回值的约束
C99中,非空类型函数必须使用带返回值的return语句。
扩展的整数类型

对整数类型提升规则的改进
C89中,表达式中类型为char,short int或int的值可以提升为int或unsigned int类型。
C99中,每种整数类型都有一个级别。例如:long long int 的级别高于int,int的级别高于char等。在表达式中,其级别低于int或unsigned int的任何整数类型均可被替换成int或unsigned int类型。
但是各个公司对C99的支持所表现出来的兴趣不同。当GCC和其它一些商业编译器支持C99的大部分特性的时候,微软和Borland却似乎对此不感兴趣。
GCC 支持C99,通过 --std = c99命令行参数开启。 例如:gcc --std = c99 test.c。默认情况下GCC是用的GNU89标准
C语言声明
优先级规则分析
A.声明从他的第一个标识符(名字)开始读取,然后按照优先级顺序依次读取:
B 优先级从高到低依次是:
B.1声明中被括号括起来的那部分
B.2后缀操作符:
括号()表示这是一个函数,而方括号[]表示这是一个数组。
B.3前缀操作符:星号*表示“指向...的指针”
C 如果const和(或)volatile关键字的后面紧跟类型说明符(如int,long等),那么它用做子类型说明符。在其他情况下, const和(或)volatile关键字作用于它左边的临近的指针星号。
例:
char * const *(*next)();
A 首先,看变量名(标识符)“next”,并注意到它直接被括号所括住
B.1 所以先把括号里的东西作为一个整体,得出“next是一个指向...的指针”
B 然后考虑括号外面的东西,在星号前缀和括号后缀之间作出选择
B.2 B.2规则告诉我们优先级较高的是右边的函数括号,所以得出“next是一个函数指针,指向一个返回...的函数”
B.3 然后,处理前缀“*”,得出指针所指的内容
C 最后,把“char * const”解释为指向字符的常量指针
更直观一点可以看下图
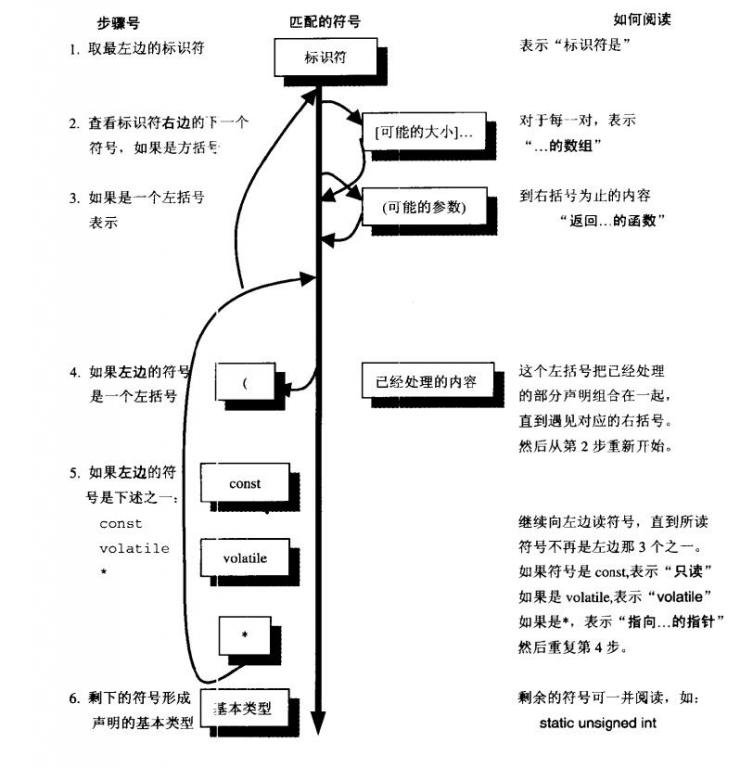
所以这个声明表示“next”是一个指针,它指向一个函数,该函数返回另一个指针,该指针指向一个类型为char的常量指针。
例子2 char *(* c[10]) (int **p)
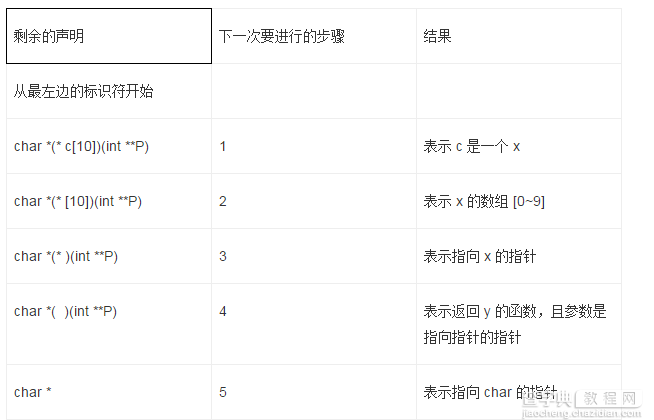
那么合起来就是c是一个函数指针数组,他的返回类型是char *,参数是int **p
以下是来自c专家编程的一个分析声明的程序
#include <stdio.h> #include <string.h> #include <ctype.h> #include <stdlib.h> #define MAXTOKENS 100 #define MAXTOKENLEN 64 enum type_tag { IDENTIFIER, QUALIFIER, TYPE}; struct token{ char type; char string[MAXTOKENLEN]; }; int top = -1; struct token stack[MAXTOKENS]; struct token this; #define pop stack[top--] #define push(s) stack[++top] = s enum type_tag classify_string(void) { char *s = this.string; if ( !strcmp(s,"const")) { strcpy(s,"read-only"); return QUALIFIER; } if (!strcmp(s,"volatile")) return QUALIFIER; if (!strcmp(s,"void")) return TYPE; if (!strcmp(s,"char")) return TYPE; if (!strcmp(s,"signed")) return TYPE; if (!strcmp(s,"unsigned")) return TYPE; if (!strcmp(s,"short")) return TYPE; if (!strcmp(s,"int")) return TYPE; if (!strcmp(s,"void")) return TYPE; if (!strcmp(s,"long")) return TYPE; if (!strcmp(s,"float")) return TYPE; if (!strcmp(s,"double")) return TYPE; if (!strcmp(s,"struct")) return TYPE; if (!strcmp(s,"union")) return TYPE; if (!strcmp(s,"enum")) return TYPE; return IDENTIFIER; } void gettoken(void) { char *p = this.string; while((*p = getchar() ) == ' '); if ( isalnum(*p) ) { while( isalnum( *++p = getchar() )); ungetc(*p , stdin); *p = '/0'; this.type = classify_string(); return; } if (*p == '*' ) { strcpy(this.string, "pointer to"); this.type = '*'; return; } this.string[1] = '/0'; this.type = *p; return; } read_to_first_identifer() { gettoken(); while(this.type != IDENTIFIER ) { push( this ); gettoken(); } printf("%s is ",this.string); gettoken(); } deal_with_arrays() { while(this.type = '[' ) { printf("array"); gettoken(); if ( isdigit(this.string[0]) ) { printf("0..%d ",atoi(this.string)-1); gettoken(); } gettoken(); printf("of "); } } deal_with_function_args() { while( this.type != ')' ) { gettoken(); } gettoken(); printf("function returning "); } deal_with_pointers() { while(stack[top].type == '*' ) { printf("%s ", pop.string); } } deal_with_declarator() { switch(this.type) { case '[' :deal_with_arrays();break; case '(' :deal_with_function_args(); } deal_with_pointers(); while( top >= 0 ) { if ( stack[top].type == '(' ) { pop; gettoken(); deal_with_declarator(); } else printf("%s ",pop.string); } } main() { read_to_first_identifer(); deal_with_declarator(); printf("/n"); return 0;
}