

其基本模式如下:
分解:把一个问题分解成与原问题相似的子问题
解决:递归的解各个子问题
合并:合并子问题的结果得到了原问题的解。
现在就用递归算法,采用上面的分治思想来解合并排序。
合并排序(非降序)
分解:把合并排序分解成与两个子问题
伪代码:
复制代码 代码如下:
MERGE_SORT(A, begin, end)
if begin < end
then mid<- int((begin + end)/2)
MERGE_SORT(A, begin, mid)
MERGE_SORT(A, mid+1, end)
MERGE(A, begin, mid, end)
解决:递归的解各个子问题,每个子问题又继续递归调用自己,直到"begin<end"这一条件不满足时,即"begin==end"时,此时只有一个元素,显然是有序的,这样再进行下一步合并。
合并:合并的子问题的结果有个隐含问题,即各个子问题已经是排好序的了(从两个氮元素序列开始合并)。做法是比较两个子序列的第一个元素小的写入最终结果,再往下比较,如下图所示:

图中:待排序数组为2 4 6 1 3 5
把2 4 6和 1 3 5 分别存到一个数组中,比较两个数组的第一个元素大小小者存于大数组中,直到两小数组中元素都为32767.
这里32767 味无穷大,因为 c语言中 int类型是32位,表示范围是-32768-----32768。用无穷大作为靶子可以减少对两个小数组是否为空的判断,有了靶子,直接判断大数组元素个数次就排完了。
在整个过程中执行过程示如下图:
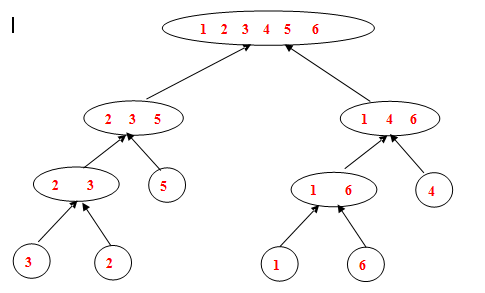
分解+执行时自上向下,合并时自下向上。
代码奉上:
复制代码 代码如下:
#include <stdio.h>
void MERGE(int *A, int b, int m, int e)
{
int l = m-b+1, r = e-m, i;
int L[l+1], R[r+1];
for(i=0; i< l; i++)
{
L[i] = A[b+i];
}
for (i=0; i< r; i++)
{
R[i] = A[m+i+1];
}
L[l] = 32767;
R[r] = 32767;
l = 0;
r = 0;
for(i=0; i< e-b+1; i++)
{
if(L[l] < R[r])
{
A[b+i] = L[l];
l ++;
}
else {
A[b+i] = R[r];
r ++;
}
}
}
void MERGE_SORT(int *A, int b, int e)
{
if(b < e)
{
int m = (b + e) / 2;
MERGE_SORT(A, b, m);
MERGE_SORT(A, m+1, e);
MERGE(A, b, m, e);
}
}
int main()
{
int A[500];
int lens, i;
printf("Please Enter the lenghth of array:");
scanf("%d", &lens);
printf("Please Enter the elements of the array:");
for(i=0; i< lens; i++)
scanf("%d", &A[i]);
MERGE_SORT(A, 0, lens-1);
printf("the result of the sort is:n");
for(i=0; i< lens; i++)
{
printf("%d ", A[i]);
}
return 0;
}