

一、概述
讲解优化查询相册图片之前,我们先来看下PM提出的需求,PM的需求很简单,就是要做一个类似微信的本地相册图片查询控件,主要包含两个两部分:
进入图片选择页面就要显示出手机中所有的照片,包括系统相册图片和其他目录下的所有图片,并按照时间倒叙排列 切换相册功能,切换相册页面列出手机中所有的图片目录列表,并且显示出每个目录下所有的图片个数以及封面图片
这两个需求看似简单,实则隐藏着一系列的性能优化问题。在做优化之前,我们调研了一些其他比较出名的app在加载大数量图片的性能表现(gif录制的不够清晰,但展示问题已经够了):
下面测试了几个常用软件
微信:
微信的图片查询速度还是非常快的,基本上进入图片选择页面,相册数据就已经查出来了,包括各个图片目录下图片的个数和封面图片的url,这个体验还是比较好的。
新浪微博:
相比较微信来说,新浪微博做的体验就比较差了,进入图片选择页面后,先是黑屏然后是白屏,连个进度条都没有,让用户以为app死掉了,等过一段时间才显示出来,这个体验较差
QQ:
QQ一上来是加载的最近100张照片,这个速度非常快,但是进入Camera相册(有5000多张)后,有一个进度条等待,我体验了下,等待的时间还是比较长的,这个体验比新浪微博稍微好点,比微信差
闲鱼:
闲鱼是做的最烂的一个,一上来是卡死四五秒,然后是黑屏两三秒,最后才显示出来
二、综合对比
经过综合对比后,就微信做的还比较好,基本上进入相册页面就能展示出所有照片,相册目录也非常快的展示出来!!!
经过我们的调研,发现微信是采用循环分页加载策略,我们优化的思路也是采用这种策略,先看优化后的效果图:
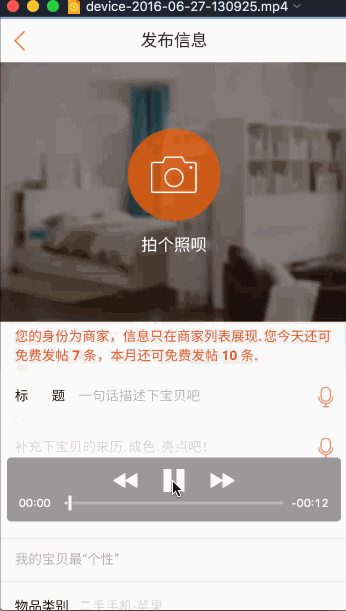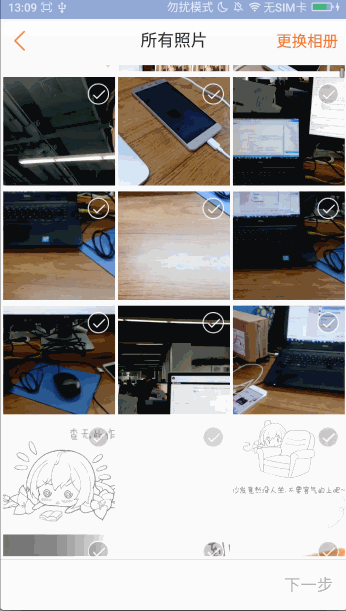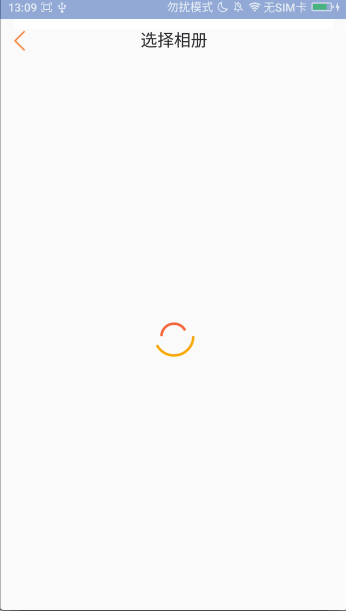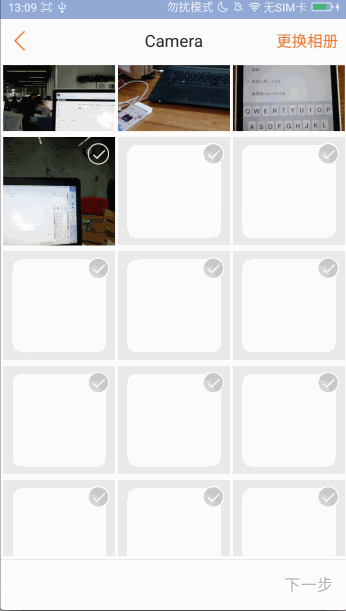
进入图片选择页面,图片能够非常快的显示出来,进入更换相册页面,图片目录也能非常快的显示出来,这里没有像微信一样做图片目录的缓存:一是因为查询速度非常快,基本上不到2秒就加载出来了,二是能够实时刷新出相册的最新数据
频繁的切换各个相册目录,图片都能非常快速的查询出来,体验还是不错的!!!
三、优化实现
优化查询相册目录
因为要列举出所有的相册目录列表,这里没有其他好的办法,直接请求ContentResolver的query方法来查询,这里为了加速查询,去掉了while循环中一些耗时的判断,将一些检测图片是否判断的逻辑移到外面去,具体用的时候再去判断
查询图片的URI
MediaStore.Images.Media.EXTERNAL_CONTENT_URI
因为我们只查询图片url和图片所在的目录
String[] projection = {MediaStore.Images.ImageColumns.DATA, MediaStore.Images.ImageColumns.BUCKET_DISPLAY_NAME};
PM要求相册按照图片的时间倒叙排列,图片的创建、修改会影响其所在目录的排序,排序按时间倒叙排列
String sortOrder = MediaStore.Images.Media.DATE_TAKEN + " DESC ";
根据这些查询条件,经过query之后得到一个Cursor,这个cursor里面就包含我们所需要的所有图片的信息,然后我们while循环遍历这个cursor,在while循环中一定不能有耗时操作
//一个辅助集合,防止同一目录被扫描多次 HashSet<String> dirPaths = new HashSet<String>(); while (cursor.moveToNext()) { // 获取图片的路径 String path = cursor.getString(cursor.getColumnIndex(MediaStore.Images.ImageColumns.DATA)); String bucketName = cursor.getString(cursor.getColumnIndex(MediaStore.Images.ImageColumns.BUCKET_DISPLAY_NAME)); if (TextUtils.isEmpty(allFolderItem.coverImagePath)) { allFolderItem.coverImagePath = path; } File parentFile = new File(path).getParentFile(); if (parentFile == null) continue; String dirPath = parentFile.getAbsolutePath(); PicFolderItem folderItem = null; // 利用一个HashSet防止多次扫描同一个文件夹(不加这个判断,图片多起来还是相当恐怖的~~) if (dirPaths.contains(dirPath)) { continue; } else { dirPaths.add(dirPath); boolean isNew = true; //判断一下是否dirPath不同,但是bucketName相同 for (PicFolderItem item : picList) { if (item.name.equals(bucketName)) { folderItem = item; item.addParentPath(dirPath); isNew = false; break; } } if (isNew) { folderItem = new PicFolderItem(); folderItem.coverImagePath = path; folderItem.name = bucketName; folderItem.addParentPath(dirPath); } } String[] array = parentFile.list(new FilenameFilter() { @Override public boolean accept(File dir, String filename) { if (filename.endsWith(".jpg") || filename.endsWith(".png") || filename.endsWith(".jpeg")) return true; return false; } }); int arrayCount = array == null ? 0 : array.length; folderItem.count += arrayCount; if (!picList.contains(folderItem) && arrayCount > 0) { picList.add(folderItem); } }
这样就能非常快速的查询出手机中所有的图片目录、目录的图片张数以及封面图url。这里主要优化了三点:
while循环中去除耗时判断
之前的代码中存在判断文件图片是否存在的代码:
public static boolean isFileExist(String path) { File file = new File(path); if (file == null || !file.exists()) { return false; } return true; }
这段代码放到while循环中是很恐怖的,我测试了下,5000多张图片都要检测的话总时间会增加三四秒。这个判断可以放到外面去,具体操作哪一个图片的时候再做具体的业务判断!
防止一个图片文件夹被扫描多次
这里添加了一个变量来存储已经扫描过的图片目录,已经扫描的就不在处理了:
//一个辅助集合,防止统一目录查询多次 HashSet<String> dirPaths = new HashSet<String>();
这块优化了之后效果还是很明显的,相同的目录不会扫描多次!
获取图片目录下图片个数
String[] array = parentFile.list(new FilenameFilter() { @Override public boolean accept(File dir, String filename) { if (filename.endsWith(".jpg") || filename.endsWith(".png") || filename.endsWith(".jpeg")) return true; return false; } });
这个file.list()方法内部是一个native方法,查询效率非常快!!!
当然获取某个目录下的图片有多少张也可以通过cursor查询的方式来获取!!!
查询某个相册目录下的所有照片
在介绍查询目录下的照片之前,我们先介绍下我们查询图片的两种策略,一种是针对目录下图片比较多的,动不动就上千上万张的那种;另一种是那种目录下图片比较少的,就几百张图片
一次加载策略
当目录下图片数量小于1000张时采用file.list这个native方法来一次加载所有图片,这个native查询效率非常快,上千张图片都是秒级查询出来
循环分页加载策略
当图片数量大于等于1000张时采用循环分页加载策略,这种策略专门针对图片数量特别多的情况,通过分页的方式先把第一页的图片加载出来,让用户能第一眼看到最新的图片,然后后台异步循环的查询下一页图片,直到所有图片都查询完成,这也是微信的查询相册策略。
一次加载策略实现
我们这里看下一次加载完策略实现代码,首先通过File的list方法将后缀为图片格式的文件过滤出来,返回一个图片路径数组
File dirFile = new File(dir); String[] list = dirFile.list(new FilenameFilter() { @Override public boolean accept(File dir, String filename) { if (filename.endsWith(".jpg") || filename.endsWith(".png") || filename.endsWith(".jpeg")) return true; return false; } });
因为我们要的是按时间倒叙进行排列的数组,所以要对上面查询出来的数组进行排序,这里用到了File文件lastModified方法
Collections.sort(strings, new Comparator<String>() { @Override public int compare(String lhs, String rhs) { Long time1 = new File(lhs).lastModified(); Long time2 = new File(rhs).lastModified(); return time2.compareTo(time1); } });
循环分页加载策略实现
这个策略借鉴了微信,通过分页的方式来一页一页的加载图片,直到所有的图片都加载完成。
这里的核心就是查询条件,将你要查询的某个目录添加到查询参数中
String selection = MediaStore.Images.ImageColumns.BUCKET_DISPLAY_NAME + " = '" + 目录名称 + "' ";
这个selection一定不能写错,不然查询不出来
因为要分页,sortOrder不是简单的按照时间倒叙来排了
String sortOrder = MediaStore.Images.Media.DATE_TAKEN + " DESC limit " + PAGE_SIZE + " offset " + pageIndex * PAGE_SIZE;
最后对Cursor进行循环遍历拿到我们要的图片路径
PAGE_SIZE是个常量,表示我们要一次查询多少条,我们这里定的是200,一次查询200条数据,pageIndex是查询第几页,从0开始
一开始的时候查询第一页的数据,当查询的数据列表大小大于等于我们要查询的PageSize大小时,我们就认为有下一页,pageIndex加1循环查询下一页,直到查询的列表大小小于PageSize。
经过上面几步优化后,加载本地相册图片基本上就没有什么问题了。我们经过真机测试,图片5549张,都能够非常快速的查询出来,堪比微信和图库。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持查字典教程网。