

众所周知,现在的独立显卡市场是NVIDIA和AMD-ATI两家的天下。尽管INTEL凭借整合图形芯片组的优势占据了集成显卡市场的半壁江山,但独立显卡一直是INTEL心中难言的痛,它一直在寻找进军独立显卡市场的切入点。早在1998年2月,INTEL曾发布了和Real3D合作设计的i740/i752独立显卡,但由于各大竞争对手的3D显卡性能遥遥领先,加上INTEL忙于自己的平台化策略,所以风光一时的i740/i752成为INTEL独立显卡的“绝唱”。时隔近10年,INTEL在平台化战略中取得了巨大成功,它为了巩固集成显卡市场、改变人们认为INTEL整合显卡性能是“鸡肋”的成见,近年来一直默默实施代号为“Larrabee”的独立显卡开发计划……
Larrabee,穿着马甲的CPU?
Larrabee与AMD、NVIDIA的通用计算图形处理器技术不同,后两者使用Stream Processing(流处理)来满足对GPU计算的需求。
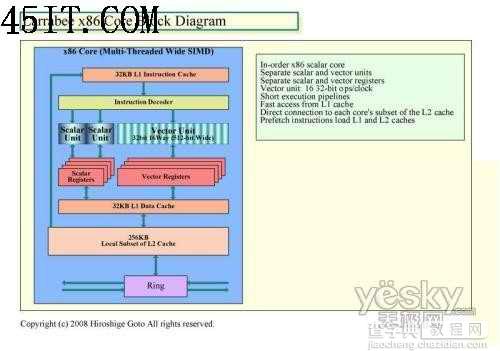
传统的x86架构
而Larrabee基于传统的x86架构,是一种可编程的多核心架构,不同的版本会有不同数量的核心,并使用经过调整的x86指令集,性能上将会达到万亿次浮点运算级别。值得注意的是,Larrabee中的处理核心为顺序执行核心,与CPU中的乱序执行核心不同。
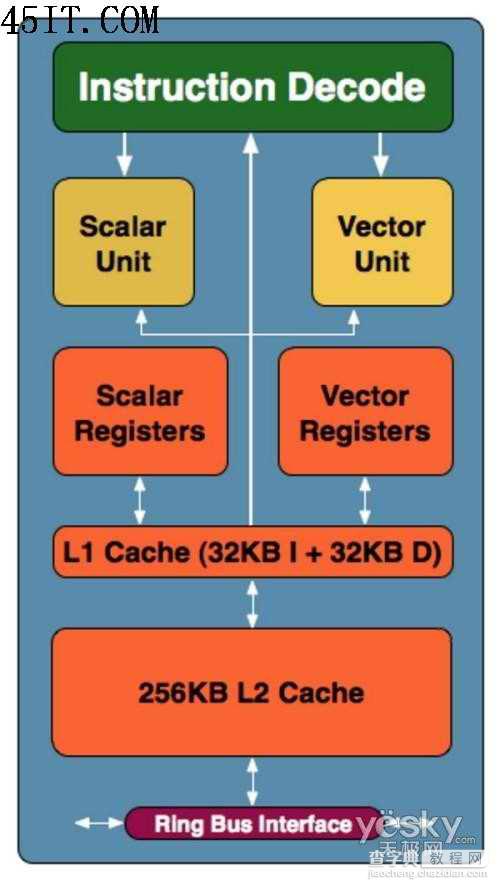
Larrabee内部工作流程
在Larrabee的内部,每一个处理核心都可以发出2条指令,这种架构是继承了最初的奔腾处理器的设计。当然在老奔腾的基础上,INTEL的工程师们也作了许多修改和提升。首先Larrabee 架构具有衍生自双指令执行 Pentium 处理器的纯量管线,并采用具有完整连贯性高速缓存架构的短执行管线。Larrabee 架构提供显著的最新改良技术,如宽幅向量处理单元、多线程、64 位延伸指令,以及精密的指令预取功能 。这将促使可用之运算能力大幅提升,并能发挥程序设计师对英 特尔架构的熟悉度及容易入门的程序开发优势。同时Larrabee的执行流水线阶层非常的短,最初的Pentium处理器的执行流水线仅有5个阶层,这意味着拥有不错的运算效率。Larrabee 将包含数个支持绘图及其他应用程序的固定功能逻辑区块,这些运算单元被谨慎选用以平衡及强化每瓦效能,并对架构的弹性与可编程化能力有所贡献。Larrabee 的原生程序设计模式支持高度平行运算应用程序,亦包括采用非规则性数据结构的运算。这项特性将促使绘图 API 的开发、新绘图算法更迅速的创新,以及在绘图处理器上执行以现有个人计算机软件开发工具软件所实作 之真正的一般目的运算。
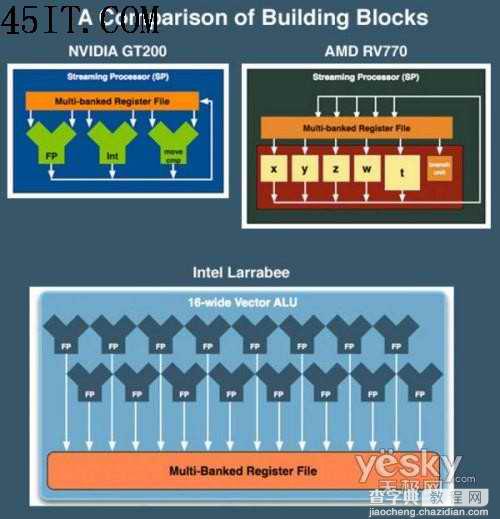
逻辑处理单元的分布
在算矢量处理单元的部分。Pentium由于设计年代久远,未曾出现过SIMD单指令多数据单元,而Larrabee在这方面有了巨大的飞跃,支持16路的矢量ALU算数逻辑单元。其运算效能非常强大,这16路可以同时执行32bit的浮点操作,这比INTEL所生产过的任何处理器都要强大许多。介于Larrabee本身的架构优势,这些矢量单元会更好的发挥其作用。INTEL的工程师们在指令的预取方面会为Larrabee做更多海量并行数据处理方面的优化。但究竟会对实际的效能产生多大的影响,目前仍是个迷。Larrabee所有超强的性能,都是基于这16路矢量ALU逻辑运算单元。请记住!这仅仅是Larrabee的一个核心,当它用于处理3D图像的时候,其内部还有很多的核心在并行工作。
此外,INTEL还对Larrabee架构指令集扩展进行了优化改进。比如16-Widevector指令,streamprocessing最佳化缓存控制指令等。另外64-bit指令也得到了支持。简单得说就是以x86基本指令集为基础加上适当的stream processing指令。另外据说当前的GPU原生指令集与CPU指令集非常相似。INTEL关于Larrabee指令扩展并没有进行详细介绍。不过估计可以有点,首先就是指令格式必须容易解码。x86指令解码多且复杂。因此为了解决这个问题,Larrabee的扩张指令最好是固定长度指令。
GPU也有L2缓存?!
由于基于Pentium 处理器架构,因此Larrabee同样沿用了完整的L1/L2缓存设计,这也是目前GPU所不具备的。

Pentium处理器架构
在L1高速缓存容量方面,其中指令缓存为32KB,L1数据缓存为32KB和,这个比各自为8KB的Pentium处理器相比提升了4倍。 同时每一个处理核心都具备256KB的L2高速缓存,未来Larrabee最初的二级缓存容量为4M,这意味着Larrabee最少有16个内核。
INTEL Core 2 Duo Hypothetical Larrabee
# of CPU Cores 2 out of order 10 in-order
Instructions per Issue 4 per clock 2 per clock
VPU Lanes per Core 4-wide SSE 16-wide
L2 Cache Size 4MB 4MB
Single-Stream Throughput 4 per clock 2 per clock
Vector Throughput 8 per clock 160 per clock
根据INTEL所述,这种256KB的缓存尺寸是专门针对Larrabee所设计的。一般来说在Larrabee进行OpenGL/DirectX渲染的时候,许多纹理都是基于64X64或128X128像素规格的,他们的色深一般为32bit,另带有32bit的Z缓冲,这些大约会消耗128KB的空间,同时Larrabee的处理核心还有128KB的空间可以加载其他的数据。
AMD RV770 NVIDIA GT200 INTEL Larrabee
Scalar ops per L1 Cache 80 24 16
L1 Cache Size 16KB unknown 32KB
Scalar ops per L2 Cache 100 30 16
L2 Cache Size unknown unknown 256KB
#p#
独特的显存架构
在显存控制器方面, AMD和NVIDIA的GPU使用的是64bit的显存控制器,并且在芯片内只有一组控制器。鉴于INTEL的Larrabee采用多核心设计,内部需要更多的显存带宽, Larrabee将采用1024-bit双向环形总线,单向传输位宽为512-bit。在加上GDDR5显存的助力,Larrabee将会有不错的性能表现。目前的GDDR5显存颗粒还十分昂贵,不过相信到了2010年的时候,会迅速普及,价格自然也会降低到一个比较合理的价位。

嵌入式存储架构
值得一提的是,AMD公司已经在它的GPU中放弃了他们的环形显存控制器架构,转而采用更先进的片上嵌入式存储,因为他们的GPU需要更加强大的存储带宽。AMD认为环形的总线会将数据直接排挤送出,这种线路设计会相对简单许多,它可以大幅减少芯片的复杂程度,不过他的缺点也比较明显,它需要一根很长的电线贯穿整个芯片。并且无论接收方是否需要,都为所有的接收端提供了较高的数据带宽。因此如果内存接收方需要更高的内存,或者需要提高系统总线的带宽的话,提供一条双向的带宽就可以轻松解决。INTEL可能有比AMD更高明的环形总线方案。因为Larrabee支持超高速相关性缓存,并且可以跨越核心通信。L2高速缓存可以被分割为2个部分,同时可以用环形总线保持他们数据的一致性。这样可以促进信息更好的被传递,也让繁重的数据处理变得更加轻松。如果Larrabee所有的处理核心都通过一个双向的环形总线连接,每个方向提供512bit的位宽。这条总线的工作频率,可能与Larrabee的主频相同。我们假设一下Larrabee的运行频率为2GHz以上,那么这条总线将会提供非常高的带宽吞吐量,而且它的工作频率要远远高于AMD的GPU。
SLI、交火不算什么,Larrabee的多内核设计!
目前的GPU全是采用单核芯片设计,图形显示系统要想达到更高的性能只能采用双GPU设计或双卡、四卡并联运行方案。这在成本上往往是用户所不能接受的。而在Larrabee上,INTEL采用多核心设计,这也将是首款采用多核设计的GPU。根据INTEL初步的计算,最初Larrabee的核心数量将会是16个核心,今后按照翻倍的步进也许会升级到32个核心。这是因为要应付目前主流的3D图形的运算,起步至少要16个核心才可以从容应对,但是24个核心的产品也是有可能的,毕竟以目前的生产工艺来看做到这一点完全是没有问题的。

半导体芯片核心
目前我们的半导体芯片核心面积可以做到286平方毫米,NVIDIA的GT200和AMD的RV770就处在这个层次上。因此在Larrabee集成更多的处理核心应该并非难事。假设INTEL要想集成40个处理核心,那么至少需要572平方毫米的芯片。事实上NVIDIA的GT200使用的是65nm制造工艺技术,如果INTEL用最为先进的32nm制造工艺技术,那么芯片的尺寸还会大幅缩小。就目前的INTEL 45nm制造工艺来说,芯片的核心面积可以减小至少50%,但是根据INTEL的说法,只要转产到45nm,甚至可以减小到60~70%的样子。届时Larrabee将能集成更多的处理核心。INTEL推测,40个核心45nm版本的Larrabee其核心面积约为370平方毫米。像NVIDIA的产品线一样,INTEL也会将芯片根据核心数量分成不同的档次,面向不同人群推出。
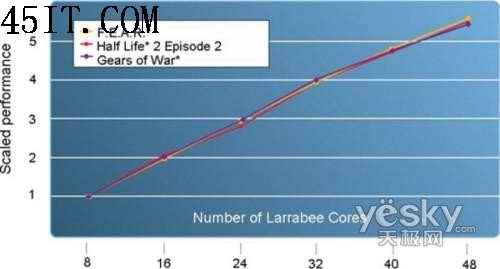
游戏性能与核心数量的增长趋势
根据INTEL的说法,这种特性在《战争机器》、《F.E.A.R.》、《半条命2:第二章》等游戏中表现最明显,实际性能基本随着核心数量呈线性增长趋势。如果8核心的性能算作1,那么16核心就约等于2、24核心约等于3、32核心约等于4。如果一直这样增长下去,那Larrabee的实力将是恐怖的。不过INTEL也承认,随着核心数量的继续增多,这种线性关系会逐渐减弱,到了40核心只有3.8-3.9,48核心就仅仅4.4-4.6了,64核心甚至可能都不到7。因此如果解决多核心中复杂的数据共享问题及功耗问题,这都是INTEL需要面对的。
除此之外,Larrabee还同时能够支持4路硬件线程。而Larrabee也能够在CPU内核心进行4组套转换。INTEL CPU比如Nehalem都支持2-way多线程,Larrabee则为4-way multi-threadCPU。而GPU产品中支持多线程的则很少。GPU产品通常配备有数十以上的线程硬件转换功能。比如GeForce GTX 200(GT200)在32寄存器/线程时转换为16warp(NVIDIA用语)。根据Larrabee的资料,硬件多线程设计是为了在进行编译的时候减少二级缓存的等待时间为目的。这与GPU的硬件多threading不同。 另外 Larrabee的硬件多线程比GPU少的原因是架构上的不同。值得注意的是,INTEL指出Larrabee“全面支持IEEE标准单、双精度浮点运算”,但没有透露具体指标。AMD和NVIDIA显卡在单精度方面表现都很出色,RV770系列已经轻松超过1TFlops,不过双精度性能还相差甚远,比如Tesla的单精度性能可达900-1000GFlops,双精度就只有100GFlops左右。如果出Larrabee全双精度浮点运算的话,那么它的通用运算能力要远远强于当前的GPU。
尽管INTEL进军独立显卡市场的野心已然明确,但据消息来源表示,目前很多细节还处于混沌状态。INTEL将会在今年第四季度公开发布详细完整的独立显卡产品线roadmap。到那个时候,Larrabee显卡才会变得更加清晰。相较于GPGPU来说,它最大的优势就在于采用了大家熟悉的x86架构。目前多数的软件工程师仍不熟悉如何将GPU应用在多任务处理及平行运算上,这点就占了不少优势。如果顺利的话,INTEL将肯定在2008年展示Larrabee系列独立显卡。根据比较可靠的消息来看,Larrabee项目其实是隶属于Tera-Scale计划(“万亿级别计算研究项目”。这个计划的重要工作内容,就是分析未来10年内人们对电脑及服务器的应用需求。这一计划涉及的研究领域非常广泛,共有超过 400 间大学、美国国防部高等研究计划局 (DARPA) ,以及像是微软与惠普等相关公司,共同为 Larrabee 应用进行研究。
.pb{} .pb textarea{font-size:14px; margin:10px; font-family:"宋体"; background:#FFFFEE; color:#000066} .pb_t{line-height:30px; font-size:14px; color:#000; text-align:center;} /* 分页 */ .pagebox{overflow:hidden; zoom:1; font-size:12px; font-family:"宋体",sans-serif;} .pagebox span{float:left; margin-right:2px; overflow:hidden; text-align:center; background:#fff;} .pagebox span a{display:block; overflow:hidden; zoom:1; _float:left;} .pagebox span.pagebox_pre_nolink{border:1px #ddd solid; width:53px; height:21px; line-height:21px; text-align:center; color:#999; cursor:default;} .pagebox span.pagebox_pre{color:#3568b9; height:23px;} .pagebox span.pagebox_pre a,.pagebox span.pagebox_pre a:visited,.pagebox span.pagebox_next a,.pagebox span.pagebox_next a:visited{border:1px #9aafe5 solid; color:#3568b9; text-decoration:none; text-align:center; width:53px; cursor:pointer; height:21px; line-height:21px;} .pagebox span.pagebox_pre a:hover,.pagebox span.pagebox_pre a:active,.pagebox span.pagebox_next a:hover,.pagebox span.pagebox_next a:active{color:#363636; border:1px #2e6ab1 solid;} .pagebox span.pagebox_num_nonce{padding:0 8px; height:23px; line-height:23px; color:#fff; cursor:default; background:#296cb3; font-weight:bold;} .pagebox span.pagebox_num{color:#3568b9; height:23px;} .pagebox span.pagebox_num a,.pagebox span.pagebox_num a:visited{border:1px #9aafe5 solid; color:#3568b9; text-decoration:none; padding:0 8px; cursor:pointer; height:21px; line-height:21px;} .pagebox span.pagebox_num a:hover,.pagebox span.pagebox_num a:active{border:1px #2e6ab1 solid;color:#363636;} .pagebox span.pagebox_num_ellipsis{color:#393733; width:22px; background:none; line-height:23px;} .pagebox span.pagebox_next_nolink{border:1px #ddd solid; width:53px; height:21px; line-height:21px; text-align:center; color:#999; cursor:default;}