

如果没有使用过 Web页面信息采集功能请参考此文。
这里要给大家做示例的网站是新浪的 考古发现频道 ,这是个比较通用和实用的规则。
一、建立采集规则
点击系统左侧的功能管理信息采集管理Web页面信息采集进入Web页面信息采集的界面。
点击界面中的添加采集规则按钮,进入添加采集规则界面。
1、采集规则基本信息
基本信息包括采集规则的名称、采集的网站域名以及其他的采集参数设置,如下图:
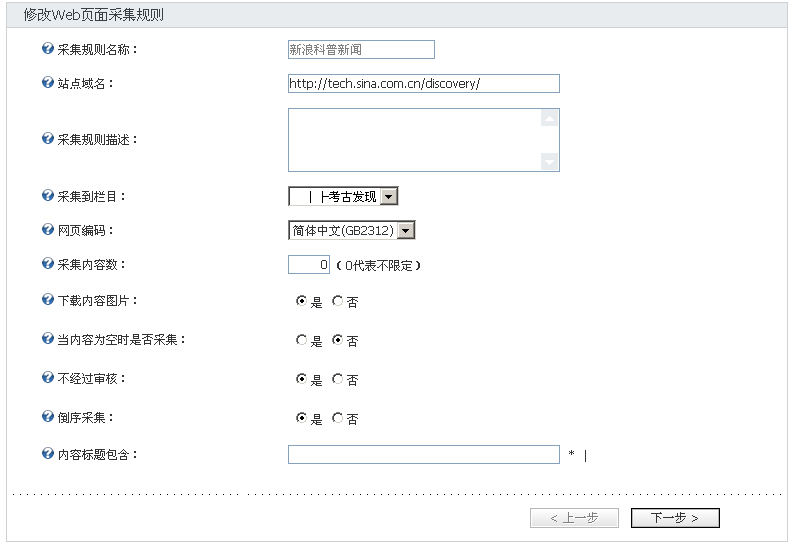
采集规则名称以及站点域名您可以取任何您觉得易记的名称,建议使用目标源的名字及域名以便于日后管理。
网页编码必须和采集网站的编码一致,一般使用简体中文(GB2312)。
采集内容数表示需要采集的条数,默认为0,代表采集全部内容。
下载内容图片项为确定是否下载采集内容中的图片到自己的服务器,以防对方网站的图片地址无法访问。
内容标题包含为过滤信息,只采集含特定字符串的标题内容。
其他参数请参考页面帮助。
2、采集内容列表信息
列表信息包括采集列表的地址以及采集内容地址必须包含的字符串等信息,用于获取采集内容的地址集合,如下图:
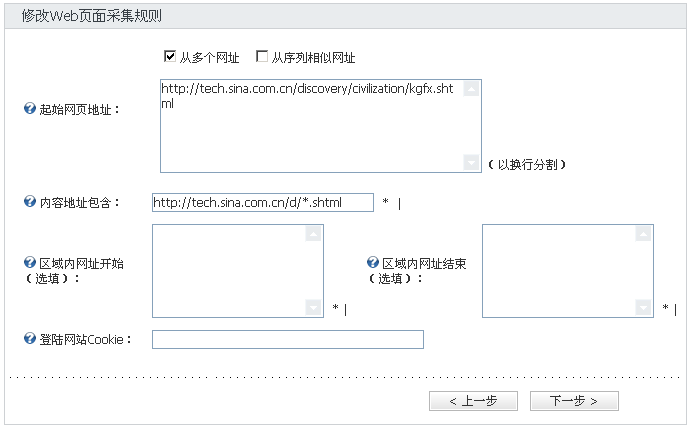
以新浪考古发现频道为例,起始网页地址为列表页的地址/discovery/civilization/kgfx.shtml。
由于考古发现频道没有翻页,起始网页地址只需要选择从多个网址,如果有翻页还需选择从序列相似网址并填入翻页数目。
内容地址包含用于过滤采集的内容地址,系统将从列表页中选择指定格式的地址作为内容页面的链接。如上图所示,系统仅采集包含/d/*.shtml字符串的内容页面,其中*代表任意字符。
区域内网址为页面某一部分的页面开始和结束,系统将采集此部分内所有的内容地址。此项可不填。
登录网站Cookie用于采集需要登录的网站,登录网站后获取到cookie信息并填入即可。此项可不填。
3、采集内容页面信息
内容页面信息包括需要采集的页面的信息,包括标题、内容、作者等,如下图:
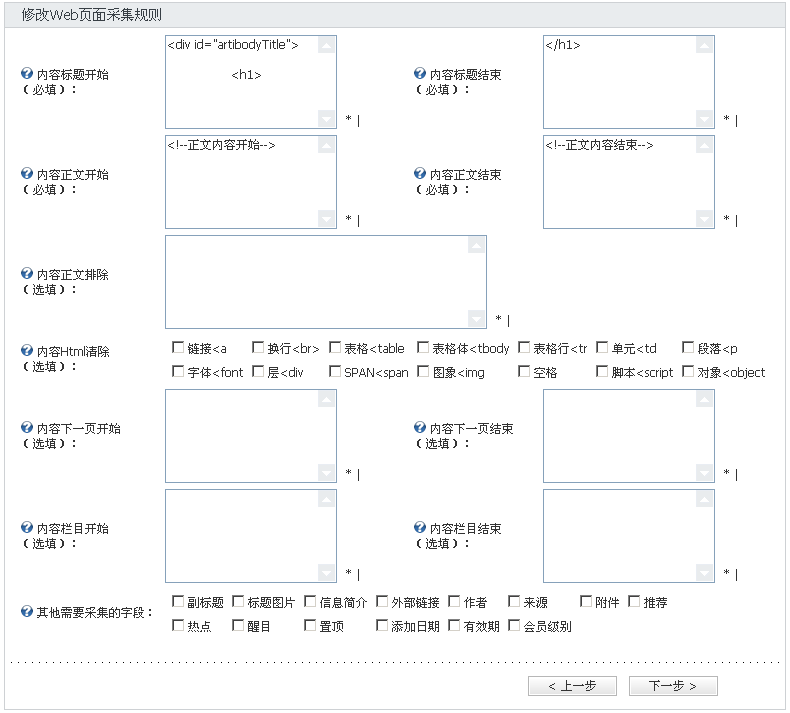
以新浪考古发现频道为例,首先进入内容页面,在浏览器中选择查看源文件获取到内容页面的代码。
在代码中找到内容标题,然后找到标题前面和后面的代码,拷贝到内容标题开始以及内容标题结束项中。
内容正文、内容栏目、内容翻页等元素与内容标题相同,找到对应代码后摘录代码之前及之后的一段代码并填入对应项中。

除默认的内容标题、正文外其他字段同样能够采集,在上图其他需要采集的字段中选择对应的字段即可。
需要注意的是内容正文排除和内容Html清除,这两项能够从内容正文中过滤不需要的信息,如广告等。
接着点击下一步便完成了Web页面信息采集规则的添加工作。
添加完成Web页面信息采集规则后接下来需要测试此规则能否正常工作。
二、测试采集规则
点击界面中的测试按钮,进入测试采集规则界面。

点击获取链接按钮后系统将获取采集频道的内容列表,如果采集规则参数正确,系统将把所有需要采集的内容列在下方。
如果点击获取链接后没有列出内容页列表则证明采集规则中采集内容列表信息参数设置需要修改。通过获取链接,可以知道采集内容列表信息的参数设置是否正确。
点击获取内容按钮后系统将采集指定的内容页并将采集到的字段信息显示在右侧。通过获取内容,可以知道采集内容页面信息的参数设置是否正确。
一般需要经过几次测试+修改的过程一个采集规则才能够正式使用。
测试通过后下一步便可以开始正式采集页面了。
三、开始采集
点击开始采集链接开始采集Web页面内容,如下图:
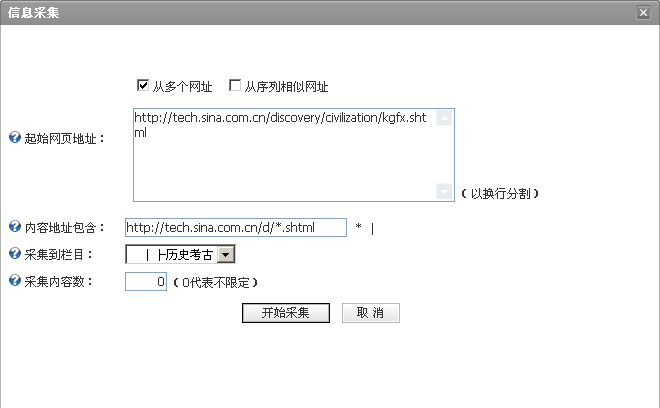
采集界面中会列出可能需要修改的参数,一般一个采集规则可以采集对应网站的所有页面,不同的是每次采集的频道页地址不同,所有可以在信息采集界面中修改采集地址以及采集到的栏目,从而重复利用所加的采集规则。
至此,采集完毕。
四、采集规则导入导出
采集规则能够保存为xml文件并在系统中导入导出,本示例对应的采集规则可以右键下载,选择目标另存为将采集文件保存到本机。
下载采集规则文件后在Web页面信息采集管理界面中点击导入采集规则,出现下图:
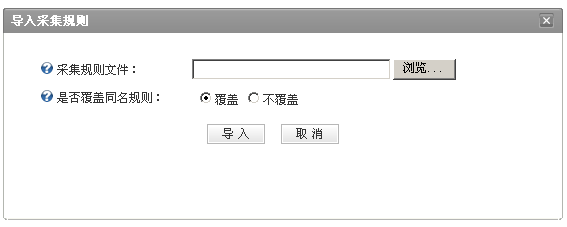
在上图中点击浏览,选择上一步下载的采集规则文件并点击导入,采集规则导入后将可以直接使用。
同时系统中的所有采集规则可以导出为xml文件。